Fonemy w roli głównej
Trochę fonetyki.
Przy okazji dokładnego przeglądu pracy logopedycznej członka sieci profesor Tomatis przeprowadził w swoim paryskim laboratorium analizę sonograficzną wybranych fonemów.
Różnicowanie fonetyczne należy bezspornie do zawodowych trosk logopedów. W gruncie rzeczy nie jest ono niczym innym niż różnicowaniem słuchowym wobec dźwięku — a tym bardziej wobec mowy. Mowa zaś składa się z następstwa dźwięków, które wyznaczają łańcuch wypowiadanej kwestii: powiązanie liter, sylab, wyrazów, składających się na zdanie, z którego wyłania się znaczenie całościowe, samo zaś rodzące się z wartości semantycznych poszczególnych komponentów słownych. Sens uruchomionej struktury, podtrzymywany przez rytm i intonację potoku słownego, zostaje ostatecznie zestrojony przez kompozycję kontekstu.
To dlatego udział słuchu jest tak istotny.
Wydaje się nam pożytecznym przypomnieć podstawowe elementy działania ucha:
- Przede wszystkim, gdy ucho prezentuje się tak, jak być powinno, rozkłada się ono — zgodnie z krzywą fizjologiczną (Fletchera) — od dźwięków niskich ku wysokim, na spektrum sięgającym od 16 do 16 000 herców;
- jego krzywa nie wykazuje żadnego zniekształcenia;
- jeżeli zaangażuje się w słuchanie, może rozkładać docierające do niego dźwięki, zarówno te z łańcucha mowy, jak i te z frazy muzycznej. Zauważmy mimochodem, że w tym konkretnym punkcie mowa zbudowana jest na specyficznej muzykalności charakterystycznej dla każdego z języków;
- w grę wchodzi również selektywność. Jest to ważna cecha ucha, wymagająca paru dodatkowych wyjaśnień, jako że jest nietypowa. Odpowiada ona zdolności ucha do tego, by nie tylko różnicować wysokości tonalne, ale także rozpoznawać kierunek zmian z jednego dźwięku na drugi. Cechę tę charakteryzuje w istocie częstotliwościowa zdolność dyskryminacyjna;
- analizie podlega także lateralność słuchowa, która wpływa na sekwencyjną zdolność dyskryminacyjną zdania;
- trzeba wreszcie pamiętać, że języki — niezależnie od tego, o którym mowa — muszą dostosowywać się do możliwości słuchania poszczególnych grup etnicznych.
Nikomu nie przyjdzie do głowy twierdzić, że mowa ustna mogłaby narodzić się w społeczności złożonej z głuchoniemych. Mogła ją zrodzić wyłącznie społeczność słyszących, lepiej powiedzieć: słuchających — prawdziwych „fonetyków". Przypomnijmy stwierdzenie Daniela Jonesa w jego dziele An Outline of Phonetics, gdzie zaznacza, iż nikt nie może rościć sobie miana fonetyka, jeśli nie posiada doskonałego ucha. W gruncie rzeczy: ucha odpowiadającego cechom, które przed chwilą wymieniliśmy.
Z drugiej strony „istotne" różnice fonetyczne, ujawnione przez Szkołę Praską i wyłożone przez Trubieckiego w jego Fonologii, nie czynią nic innego, jak definiują „kanały lingwistyczne", które w rzeczywistości są niczym innym jak „kanałami" słuchowymi.
Najbardziej oczywistego dowodu dostarczają zniekształcenia fonetyczne stwierdzane u dzieci z istotnymi ubytkami słuchu. W zależności od umiejscowienia tych ubytków w skali spektrum akustycznego, łatwo jest przewidzieć, jakie będą wady wymowy. Znaczny ubytek w dźwiękach wysokich jest niewątpliwie poważnym utrudnieniem w przyswojeniu sybilantów i — w konsekwencji — w ich spontanicznej reprodukcji.
Łatwo zatem zwizualizować paralelę łączącą integrację fonetyczną z percepcją słuchową. Ucho z powodzeniem można porównać do filtra, który zapewnia integrację w miarę swoich możliwości. Przekładać będzie tym samym skutki wad swoich krzywych odpowiedzi — i to nawet wtedy, gdy w pierwszej analizie wady te mogą wydawać się mniejsze. W ten sposób, choć zniekształcenia fonetyczne są mało dostrzegalne dla ucha nieuważnego — w istocie niewprawnego — ujawnią się one koniecznie wtedy, gdy w grę wejdą bardziej złożone procesy, takie jak czytanie i ortografia.
Przechodzimy teraz do właściwej pracy nad sonograficznymi studiami fonemów.
Komentarze do fonemów
Badanie obejmuje fonemy języka francuskiego. Jako analizator zastosowano sonograf.
Pozwala on uwypuklić:
- czas rozwoju fonemu,
- analizę częstotliwościową tego fonemu w funkcji upływu czasu,
- natężenie.
- Czas zapisuje się na osi x,
- częstotliwości na osi y. Analiza sięga tu do 10 kHz (zob. ryc. 1);
- natężenie odczytuje się w zależności od mniej lub bardziej zaakcentowanej czerni śladu częstotliwościowego. Każda częstotliwość zaznacza się tu zatem swoim natężeniem względnym w stosunku do całości.
Dla przykładu zarejestrowano różne dźwięki. Oczywiście, możemy do woli stosować to, co tu pokazujemy, w znacznie szerszym zakresie — ale podstawowe elementy zostały już uwypuklone na wybranych zapisach.
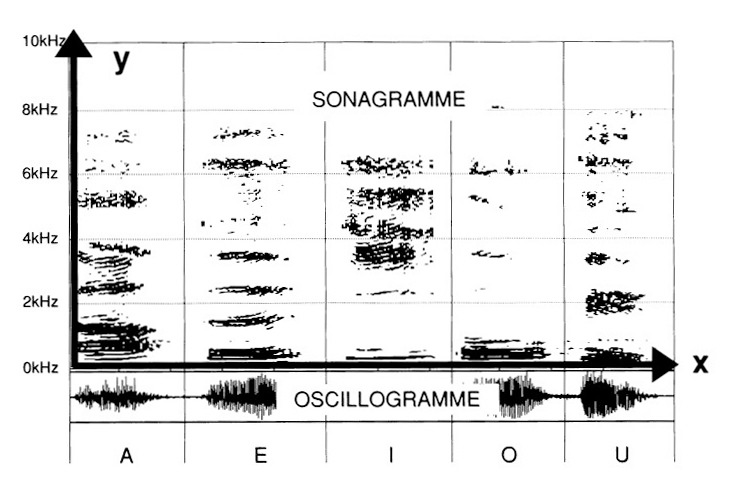
(ryc. 1)
Najpierw nagrano samogłoski: „A", „E", „I", „O" i „U".
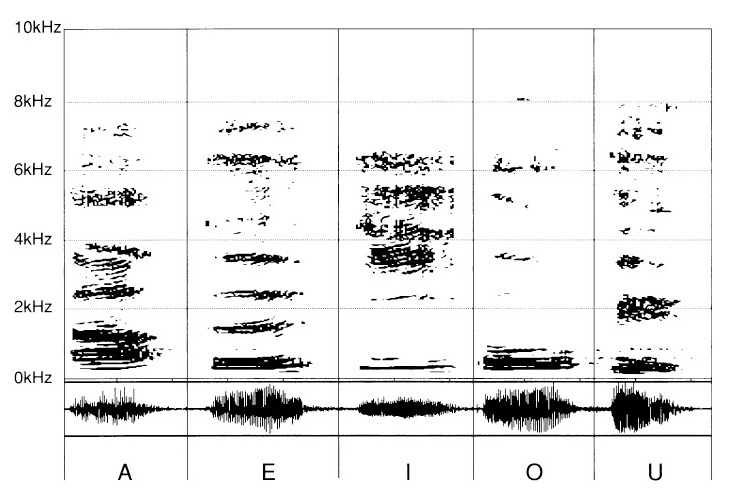
(ryc. 2)
Następnie do tych samogłosek dodano różne spółgłoski: „F", „Z", „S", „CH" oraz „V".
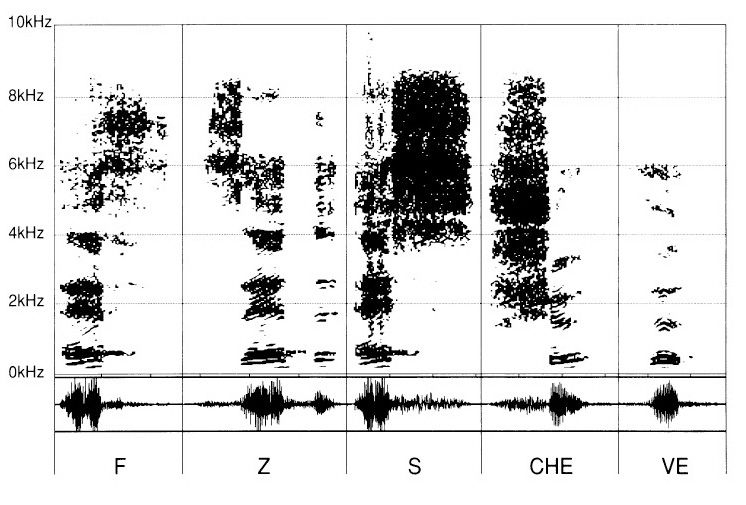
(ryc. 3)
Aby uniknąć przeładowania dokumentu, zadowolimy się dodaniem do tych spółgłosek samogłoski „E", tak jak zwykło się czynić podczas nauki czytania liter.
Na koniec przytaczamy dźwięki wynikające z dodania „N" po „A", „O".
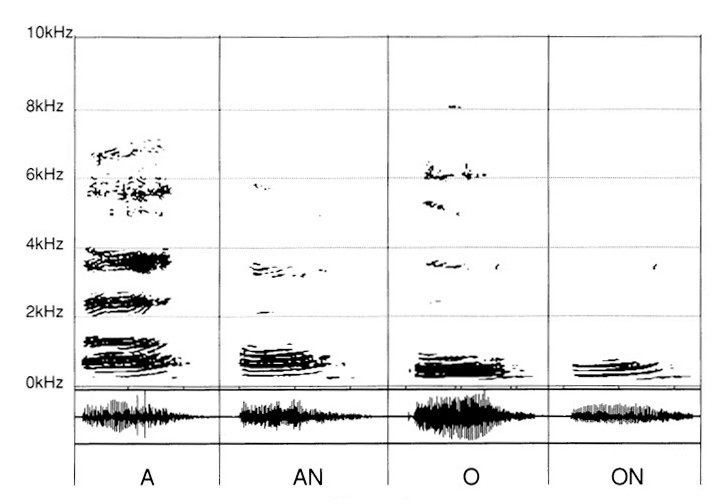
(ryc. 4)
W rezultacie kolejność spółgłosek należy odczytywać z dodanym „E". Staramy się dostrzec dźwięki spółgłoskowe (właściwie „konwoyellityczne") sprzężone z tą samogłoską, można powiedzieć „neutralną", aby nie wywoływać interferencji między spółgłoską a samogłoską.
„E" jest tu po to, by uruchomić wibrację zapłonu sybilantów wymawianych odtąd jako: „eF", „Ze", „eS", „CHe", „Ve".
Poza czasem zapisanym na osi odciętych, częstotliwości rozkładają się na osi wstępującej i pozwalają zobaczyć — w dolnej części każdego z fonemów — strefę odpowiadającą formantom, zwanym także tonami podstawowymi. Świadczą one o udziale krtani.
Na pierwszy rzut oka łatwo stwierdzić, jak różna jest strefa „tonów podstawowych". Okazuje się ona już przez to charakterystyczna dla każdego z poszczególnych dźwięków. W partii górnej wykresy odróżniają się między sobą strefami swoistymi dla każdej samogłoski. Te strefy częstotliwościowe są tym wyższe, im wyżej zapuszczamy się w rozłożone spektrum częstotliwości.
„A" okazuje się bogatsze na poziomie tonów podstawowych i harmonicznych wyższych niż „O". „I" jest szczególnie gęste w wysokich tonach, powyżej progu 2 kHz.
„Ou" prezentuje się jako „O" mniej „błyszczące" — z odpowiadającym brakiem w wyższych harmonicznych.
Spółgłoski syczące „eF", „Zed", „eS", „CHe", „Ve" również odróżniają się od siebie cechami właściwymi. Mają jednak wspólny mianownik, który znamy już — odnajdując graficzny zapis „E".
Natomiast partia sybilantów ujawnia się dla każdej z nich w sposób swoisty, jako strefa o mniej lub bardziej gęstym wypełnieniu w wysokich tonach, począwszy od 2 kHz.
Ten zestaw wykresów pozwala unaocznić wymagania związane z integracją poszczególnych fonemów.
Przypomnijmy mimochodem, że integrować dźwięk to znaczy przeprowadzić jego nagranie wysokiej jakości i zapewnić jego wierne odtworzenie — czyli odtworzenie ad integrum. Chodzi w istocie o reprodukcję wzorca. Aby to osiągnąć, niezbędne są dwa warunki:
- jeden polegający na tym, że engrafowanie odbywa się bez zniekształceń,
- drugi wymagający, by odtworzenie było jakości identycznej, bez żadnej alteracji, zwłaszcza przy emisji.
To, jak widać, problem, z którym mierzą się wszyscy, których zadaniem jest gromadzenie dźwięków, muzyki, mowy, hałasów — krótko mówiąc świata dźwiękowego. Gdy pozostajemy na płaszczyźnie czysto materialnej, dotyczącej nagrania, rzecz jest oczywista.
Ale, co dziwne, w transpozycji tych samych zjawisk dotyczących integracji, które odwołują się do przyswojenia mowy, wznosi się bariera w rozumieniu — jak gdyby nagle przesłonięty został słuchowy mikrofon, który tymczasem działa podwójnie:
- z jednej strony przy nagrywaniu,
- z drugiej w momencie emisji jako odbiornik pętli kontrolnej.
Ograniczymy się do paru spostrzeżeń, łatwych do graficznego odczytania, dotyczących najczęstszych problemów — tych, które dramatycznie komplikują życie szkolne dziecka, nie pozwalając mu pochłaniać sygnałów dźwiękowych w ich „całokształcie" ani reprodukować ich w pełni.
W tym pierwszym kontakcie weźmiemy prosty przypadek braku słuchania w wysokich tonach, na przykład powyżej 2 kHz.
Dla tych, którzy są przyzwyczajeni do podchodzenia do pojęcia słuchania, oznacza to:
- albo wykazywanie niedosłuchu odbiorczego o mniej lub bardziej zaakcentowanym charakterze,
- albo posiadanie selektywności nieotwartej powyżej tego poziomu — to znaczy niezdolność do analizy częstotliwościowej powyżej 2 kHz.
Na wykresach, które następują, wadliwe wysokie tony zostały przedstawione w postaci strefy zacienionej. Można ją sobie wyobrazić mniej lub bardziej zacienioną, a więc mniej lub bardziej zaakcentowaną.
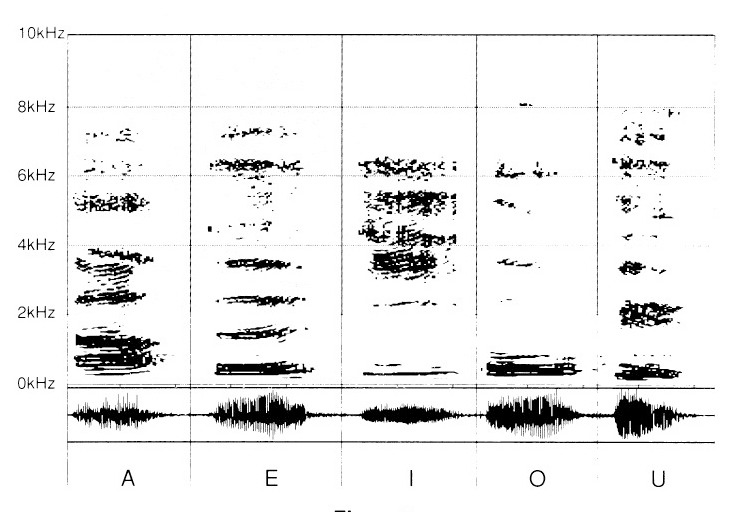
Samogłoski „A", „E", „I", „O" i „U" (ryc. 5) tracą swój blask. Ich percepcja niewątpliwie stanie się matowa, ale to na poziomie emisji zjawisko jest najbardziej uderzające. Pertynentne różnice tracą bowiem znacząco swoje znaki rozpoznawcze. Przekłada się to na wadliwą wymowę.
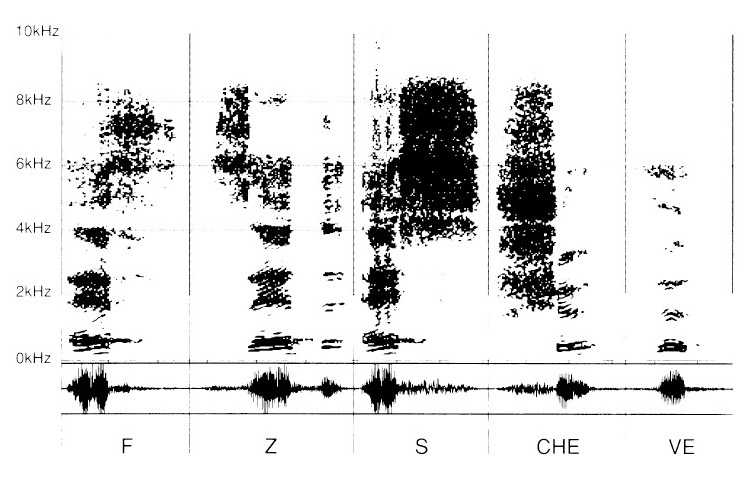
W przypadku sybilantów „F", „Z", „S", „CH" i „V" (ryc. 6) ich cechy różnicujące znikają, pozostawiając jedynie część niepertynentną — tak że staje się jeśli nie niemożliwe, to z pewnością trudne poprawne rozróżnienie poszczególnych syczących.
Wiadomo, jak częsta jest ta konfuzja. Wiadomo również, jak te problemy rozwiązują się, gdy selektywność zostaje otwarta przez edukację słuchową — bez sięgania do czegokolwiek innego na płaszczyźnie pedagogicznej.
U dziecka inną pułapką jest niemożność dostrzeżenia różnicy między „A" a „An", między „O" a „ON".
Także i tu nagrania dostarczają znaczących informacji — w tym sensie, że uwypuklają cechy różnicujące między każdą z dwóch znanych nam już samogłosek „A" i „O" a ich wypadkowymi „AN" i „ON", powstałymi przez dodanie „N".
Przy słuchaniu otwartym, działającym bez zniekształceń i bez zamknięcia selektywności — żadnego problemu. Jest praktycznie niemożliwe, aby nie dostrzec różnicy.
Natomiast w przypadku słuchu, który jeszcze nie osiągnął otwarcia selektywności — czyli, jak w przypadku poprzednim, ze strefą nieróżnicowania powyżej 2 kHz — konfuzja staje się oczywista (ryc. 7).
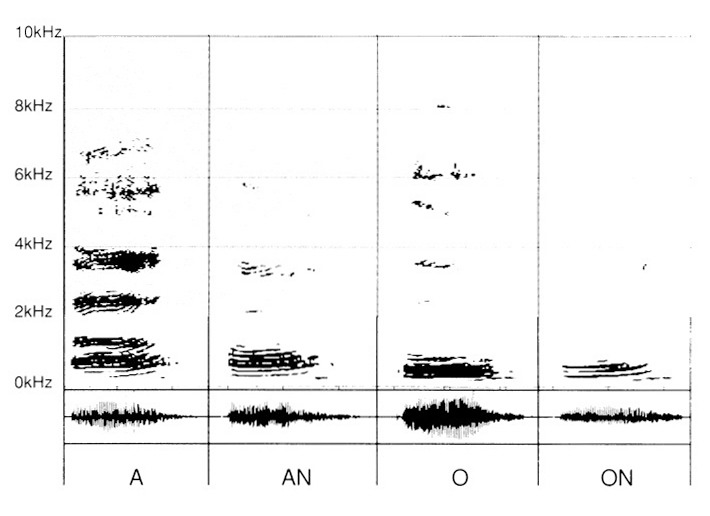
- Rozstrzygnięcie między „O" a „ON" jest naprawdę trudne do osiągnięcia.
- Dla „A" i „AN" odpowiedź może być losowa — dzięki różnicowaniu jeszcze możliwemu. W istocie dostrzega się tam pewną różnicę zagęszczenia w formantach i częstotliwościach mieszczących się między 500 Hz a 2 kHz. Jeśli selektywność jest zablokowana na 1 kHz, to nawet uważna analiza staje się bardzo trudna.

Alfred Tomatis, Paryż, 2 kwietnia 1992
Dokument oryginalny — faksymile historycznego PDF (pobieranie bezpośrednie).