Słuchanie, postawa i języki: akustyczna geografia mowy
Opracowanie na podstawie:
- A. Tomatis, Nous sommes tous nés polyglottes (wyd. wł.: Siamo tutti nati poliglotti), Edizioni Ibis, Como-Pavia, 2003.
- A. Tomatis, L’oreille et la vie, Edizioni Xenia, Como-Pavia, 2017.
- C. Campo, L’orecchio e i suoni fonti di energia, Edizioni Riza, Milano, 1993.
- C. Campo, Introduzione al metodo Tomatis, Università degli Studi di Ferrara, 2002.
- C. Campo, Il metodo Tomatis, Edizioni Xenia, Como-Pavia, 2020.
Słuchanie to proces angażujący globalnie nasz organizm, charakteryzujący także w sposób swoisty postawę: stąd psychologiczne związki między pionowością, równowagą a uchem. Lecz pociąga ono za sobą również, w pewien sposób, etno-językowe zróżnicowanie — zakotwiczając mowę w specyficznym środowisku, w którym jest używana.
Dla tych, którzy znają studia Tomatisa, twierdzenie, że pionowość i mowa idą u człowieka w parze, jest oczywiste. By wyjaśnić ten aspekt, warto otworzyć nawias i przywołać filogenetyczną ewolucję ucha — od gatunków zwierzęcych niższych, aż po człowieka. Najgłębszą i najbardziej złożoną częścią ucha — jak wiadomo — jest ucho wewnętrzne. To aparat złożony z ośrodka kontrolującego równowagę — przedsionka — oraz ze ślimaka, narzędzia analizy dźwięków i energetycznego doładowania. To coś w rodzaju skorupy wypełnionej płynami, wyściełanej komórkami sensorycznymi. Bardzo prymitywny jej zarys można zaobserwować u stułbiopława — bardzo prostego organizmu, u którego stwierdzamy nerw boczny. Nerw ten posiada osiem ośrodków będących centrami energetycznymi działającymi pod wpływem prądu wody. W toku ewolucji gatunku ten system, pozostając zasadniczo tym samym, doskonali się i wzbogaca o aparat orientacji. U niektórych ryb do tego nerwu bocznego dochodzi przewód boczny. Jest to przewód biegnący od oka, otaczający rybę. Znajduje się on po obu stronach zwierzęcia. Jest wypełniony wodą i wyposażony w otwory umożliwiające mu komunikację z otoczeniem zewnętrznym. Działa jako generator energii rozprowadzanej w postaci impulsów nerwowych, dzięki czemu ryba może się poruszać. Przewód boczny usiany jest otworami i towarzyszy mu nerw zwany nerwem bocznym.
By pełnić funkcję generatora energii, ten wypełniony wodą przewód boczny wyściełany jest komórkami sensorycznymi, zwanymi również komórkami rzęsatymi. Są to komórki wyposażone w rzęski ułożone w drobne kępki. Woda przepływająca przez przewód wprawia rzęski w wibrację o bardzo wysokich częstotliwościach. Uzyskane w ten sposób stymulacje są następnie przekazywane nerwowi bocznemu, który konwertuje je na impulsy nerwowe.
Ten sam przewód boczny pełni jeszcze drugą funkcję. Jeśli poruszanie rzęsek generuje energię nerwową, kąt, jaki rzęski te tworzą z powierzchnią przewodu, zmienia się w zależności od przemieszczeń ryby. Ruchy tych rzęsek pozwalają więc rybie poznawać naturę swoich przemieszczeń i siły prądu. Na przykład wyczuwa, czy schodzi, czy wynurza się ku powierzchni.
W łańcuchu ewolucji — i już u niektórych ryb — linia boczna ulega skróceniu i zamyka się, stając się pęcherzykiem otolitowym. Pierwszą korzyścią z tego płynącą jest to, że likwidując całą długość kolumny wody, eliminuje się również reprezentowany przez nią czynnik bezwładności.
Podobnie jak linia boczna, pęcherzyk otolitowy działa dokładnie jak dawny przewód boczny — z komórkami rzęsatymi zanurzonymi w środowisku płynnym. Tak jak linia boczna, pęcherzyk otolitowy jest wrażliwy na zmiany przemieszczeń płynów obecnie zamkniętych w jego wnętrzu. Aby zwiększyć tę wrażliwość, wyposażono go w niewielką masę wapienną — coś w rodzaju kamyka — i za każdym razem, gdy zwierzę obraca głowę, ta masa wapienna zmienia położenie i porusza otaczające ją płyny, generując w ten sposób energię i niejako mierząc swoje przemieszczenia.
Życie wodne w praktyce nie stwarzało żadnego problemu grawitacji; ale od chwili, gdy zwierzę wychodzi z wody, by żyć zanurzone w powietrzu, musi uczynić swój aparat bardziej złożonym, by odpowiedzieć na większe zapotrzebowanie energetyczne i odtąd coraz lepiej kontrolować swoją pionowość. Sądząc po szlaku, jaki obrała ewolucja, wydaje się, że postawa pionowa stanowi obecnie stadium najbardziej ekonomiczne z punktu widzenia wydatku energii życiowej i najbardziej rentowne pod względem produkcji energetycznej. U węża pęcherzyk otolitowy komplikuje się i dzieli na sakkulus, którego zadaniem jest kontrola pionowości, oraz utrikulus, który zapewnia poziomość zwierzęcia. Do utrikulusa dochodzi zarys kanałów półkolistych, których rolą będzie kontrola ruchów obrotowych. Choć aparat staje się bardziej złożony, jego funkcja pozostaje zasadniczo ta sama: generować energię i kontrolować ruchy.
Używane materiały nie uległy zmianie: są to komórki rzęsate poruszające się w płynie. Gdy u niektórych zwierząt pojawia się nowa część zwana lagena, można zauważyć, że niektóre z tych zwierząt znacznie podnoszą głowę. Lagena jest najbardziej rozwinięta u ptaków, u których znajduje się zarys ucha środkowego.
Po lagenie nastąpi ślimak, którego obecność wyznacza pionowość. Jest on także swoistym narzędziem analizy dźwięków.
Filogenetyczna ewolucja ucha — od stułbiopława do człowieka.
To te różne elementy tworzą u człowieka labirynt, czyli ucho wewnętrzne. Jest to generator energii, który jednocześnie pozwala kontrolować wszystkie ruchy ciała. Naturalnie, samo ucho nie służyłoby do niczego. Zamknięte jest w skorupie, która je uformowała — w labiryncie kostnym — z którego wychodzą nerwy biegnące od utrikulusa, sakkulusa, każdego z kanałów półkolistych, by utworzyć tzw. nerw przedsionkowy. Ma on w pewnym miejscu zwój i ciągnie się aż do utworzenia jąder przedsionkowych. Jest ich cztery i funkcjonują dokładnie jak pierwotny mózg. Dzięki nerwom wychodzącym z jąder przedsionkowych docierają one do wszystkich mięśni ciała — bez wyjątku.
Za każdym razem, gdy musimy przyjąć jakąkolwiek postawę lub pozycję równowagi, dzięki interwencji obu labiryntów wysyłana jest do mięśni odpowiednia informacja. Każdy mięsień odsyła informację, by zasygnalizować swoje położenie i swój stan. Informacja ta wraca do przekaźnika pośredniego znajdującego się w móżdżku, połączonego z przedsionkiem przez jądra przedsionkowe. Wszystkie ruchy mięśniowe przechodzą tak przez labirynt.
Zamknijmy ten filogenetyczny i anatomo-fizjologiczny nawias i — w świetle tego, co właśnie powiedzieliśmy — ukażmy związek między mową a postawą. Aby jak najlepiej wykorzystać tysiące komórek rzęsatych ucha wewnętrznego, przedsionek i ślimak muszą być zorientowane w przestrzeni w taki sposób, by utrikulus znalazł się w pozycji poziomej, a sakkulus — w pionowej; to ta pozycja daje największą liczbę stymulacji na poziomie komórek. To w tej pozycji powstaje największa stymulacja mózgu. A to głowa, ustawiając się prawidłowo, umieszcza labirynt wedle tych osi — a dobra postawa głowy zależy od dobrego rozkładu sił napięciowych utrzymujących ciało w pionie. Ta pionowość z kolei realizowana jest za pomocą obwodu przedsionek–móżdżek–układ mięśniowy.
Ucho, które potrafi dobrze słuchać — a zwłaszcza dźwięki wysokie — sprzyja więc, przez cybernetykę przedsionkową, dobrej pionowości. Mowa, która opiera się na bardzo subtelnej zdolności ucha ludzkiego do analizy drobnych różnic tonalnych odpowiadających rozmaitym dźwiękom zawartym w języku, wymaga dobrego słuchania i dobrej pionowości.
Jeśli bowiem spróbować mówić na czworakach i długo prowadzić w tej osobliwej pozycji rozmowę, zacznie odczuwać się dyskomfort, który nie ma nic wspólnego z pozornym nieuporządkowaniem sytuacji, lecz wynika z trudności postawienia się w słuchaniu. Dla Tomatisa bowiem nadstawiać ucha to także napinać całe ciało ku słuchaniu — w tym celu konieczne jest ofiarowanie informacji najbardziej wrażliwych części osoby. Przednia część nabłonka skórnego jest najbogatsza we włókna sensoryczne zdolne uchwycić — w pewnej mierze — sensacje odpowiadające naciskom. Ta sensoryczna sieć potrafi również przekazywać informacje układowi szkieletowemu, dodając transmisję kostną do stymulacji informacyjnych. Odtąd słuchanie się poprawia i przekształca postawę, która z kolei pozwala słuchaniu się doskonalić — dzięki komunikatowi, który zaczyna docierać w sposób wierniejszy. Działania, reakcje i kontrreakcje ślimakowe i cielesne kryją w swoim mechanizmie najważniejsze klucze do pionowości. Ewoluują one równolegle z mową, która dla Tomatisa nie jest niczym innym jak biologicznym przekładem aktu słuchania. Wszystko bowiem pozwala dostrzec, że istnieje najpierw głuchy dialog w głębinach struktury językowej, następnie mowa potoczna złożona z warunkowań odpowiadających doraźnym potrzebom; potem przychodzi językowość społeczno-kulturowa, która powinna być afirmacją funkcji słuchu i w pewnej mierze pozwala dostąpić zrozumienia nauczania, którego jest nośnikiem. Wreszcie, w ostatnim stadium, pojawia się mowa refleksyjna wytwarzana przez głębokie słuchanie — otwierająca dialog z samą myślą — aż do uzyskania zwerbalizowanej sekrecji, która nie jest niczym innym jak myślą w jej substancji, czyli „logosem wcielonym", parafrazując Tomatisa.
Mowa a obraz ciała
Intymna korelacja między uchem a globalnym obrazem ciała przechodzi przez punkt ich połączenia: mowę. Jest ona owocem słuchania i wymaga — by być kontrolowaną, potwierdzaną, prowadzoną aż w jej najdrobniejszych modulacjach — by ucho było otwarte, i to otwarte aż do słuchania. To niemało, gdyż słuchanie wprowadza świadome pole w rzeczywisty wymiar.
By zorganizować to szczególnie delikatne urządzenie, ucho kieruje — by nie powiedzieć narzuca — całą konstrukcję ciała na poziomie jej reprezentacji umysłowej, odbicia obrazu korowego. Tak więc osoba, która zdoła nabyć idealnie wyrażoną mowę — a to już bardzo, gdy się to udaje — kończy ustawianiem się w postawie posturalnej odpowiadającej idealnej postawie, jaką może osiągnąć ten, kto mówi według uznanych za doskonałe norm. Zjawisko jest jeszcze bardziej wyraziste u śpiewaków i aktorów, którzy z powodów zawodowych muszą uzyskać doskonałą emisję dźwięków, jakie mają silnie kontrolować. Postawy są bardzo wymowne i pozwalają zrozumieć, w tym przypadku, konieczność dobrze określonej postawy scenicznej w celu wykonania aktu wymagającego doskonałości realizacji. Dzięki Oreille Électronique — aparatowi wynalezionemu przez Tomatisa do reedukacji słuchania — łatwo jest zaobserwować zmiany posturalne związane z wprowadzanymi modyfikacjami słuchowymi. Narzucając, dzięki elektronicznym przełączeniom, słuchanie bogate w wysokie częstotliwości, obserwuje się w momencie ożywienia fonacji znaczącą korelację posturalną. Zauważa się przede wszystkim wyprostowanie kręgosłupa i wyraźne otwarcie klatki piersiowej; do tego dochodzi poszukiwanie lepszej prostości grzbietowej dzięki obrotowi miednicy przez antewersję części łonowej. W tym samym czasie twarz odpręża się i porusza się harmonijnie, bez napięcia, a głos się rozjaśnia. Bardzo trudno zaobserwować na przykład w klasie dziecko uważnie śledzące lekcje, gdy jest zwalone na krzesło. I byłoby trudne uruchomienie mechanizmu słuchania, utrzymując taką postawę. Co więcej, ten, kto mówi, ma poczucie, że jest słuchany, gdy jego rozmówca trzyma się w prostej postawie — nie zaś gdy wydaje się opadnięty na samego siebie.
Tomatis proponuje ćwiczenie pozwalające zrozumieć, czym jest postawa słuchania. Nazywa to treningiem audiogennym. Można go przyjąć, zaczynając z pozycji siedzącej na stołku ustawionym tak, by mieć kolana nieco niżej niż miednicę, co sprzyja właściwemu ustawieniu tej ostatniej. Z zamkniętymi oczami głowa szuka swojego punktu równowagi, by sprzyjać optymalnej percepcji wysokich tonów obecnych w otoczeniu. Następnie chodzi o właściwą mobilizację muskulatury ucha środkowego. Zaczyna się od wyobrażenia sobie, że cała skóra głowy zbiera się w górnej części głowy — wertekstrze — odpowiadającej punktowi tonsury mnichów. Po czym zmarszczki poziomo bruzdujące czoło zaczynają znikać. Jeśli wszystko idzie dobrze, czuje się wyraźne wrażenie u nasady włosów, z odczuciem chłodu w tej części czaszki.
Po udanej operacji wyobrazimy sobie teraz poszerzanie czoła — tak, jakby skóra chciała dotknąć ścian pokoju, w którym się znajdujemy. Zaraz potem ściągnijmy tę skórę, by zebrała się w tym samym punkcie, w którym uformowaliśmy „kok" ze skóry głowy — mocno ściskając, by skóra się napięła. W tym momencie, jeśli operacje zostały prawidłowo wykonane i głowa została utrzymana w pozycji wskazanej na początku, pionowe zmarszczki na czole, jeśli takie są, zaczynają się wygładzać i zaczynają zachodzić pewne modyfikacje wazomotoryczne: twarz się rumieni i rozgrzewa, potem traci kolor, a oddech staje się szerszy i głębszy, bardziej swobodny — naprawdę zaczyna się odblokowywać, stawać się tym, czym normalnie powinien być.
Powieki, dotąd celowo opuszczone, zamykają się pod własnym ciężarem, z drżeniem w ich części zewnętrznej. W tym momencie, wciąż wyobrażając sobie, weźmy skórę twarzy poniżej czoła i rozciągnijmy ją, aż dotknie ścian pokoju. Następnie zbierzmy także i tę partię skóry, by zebrała się w małym koku na szczycie głowy. Dołączą do niej dwa uszy, które przesuwają się na szczyt czaszki.
Działanie na poziomie skóry będzie wyraźne. Powstanie wrażenie, że na twarz nałożona została cienka warstwa kauczuku — tak silnie odczuwa się działanie w mięśniach twarzy. Jest to coś jak „fizjologiczny lifting". Co więcej, jednocześnie górna warga pozostawiona zostaje opierając się na dolnej jak na kapitelu. Ustanawia się tym samym równowaga między mięśniami okrężnymi warg a tymi działającymi na ich kąciki, podczas gdy żuchwa utrzymuje kontakt z górną szczęką bez kurczów. W tym momencie twarz zaczyna przyjmować wyraz bardzo odprężony i wypoczęty — jakby uwolniony od śladów, jakie troski zostawiają na skórze. Doszedłszy do tego etapu — prawdę mówiąc, bardzo przyjemnego, tak że ten, kto go doznaje, chciałby go zachować na zawsze — zachowując twarzowe ukojenie, próbujemy postrzec otoczenie. W tym momencie spostrzega się, że coś się zmienia. Szmery zaczynają się oczyszczać, przyjmują barwę bardziej klarowną. Dźwięki niskie się przyciszają, podczas gdy rośnie obecna w nich składowa wysoka. Wszystko wydaje się stawać się jaśniejsze i żywsze.
Jeśli próbuje się w tych warunkach słuchać własnego głosu, ma się wrażenie postrzegania go po raz pierwszy — z większą barwą i bogatszego w harmoniczne. Co więcej, ma się wrażenie, że to prawe ucho prowadzi słuchanie, a lewe ucho ciągnie do punktu zlokalizowanego na szczycie głowy — dokładnie tam, gdzie zebraliśmy mały kok. Fizjologicznie nazywa się to punktem fuzji.
Ideałem byłoby, gdyby udało się od tego momentu postrzegać własny głos jakby zakotwiczony w tym punkcie. Ten sposób postrzegania dźwięków i własnego głosu ma psychologiczne, jeśli można tak powiedzieć, korelacje: możliwość lepszego obiektywizowania własnych relacji z sobą i z innymi.
To właśnie taką postawę słuchania przyjmują dobrzy śpiewacy w sposób nieświadomy, w chwili „zapalania" swojego głosu. To postawa słuchania wolnego, rozmyślnego, bez przeszkód, w której osoba może słuchać siebie i słuchać innych bez interferencji płynących z „limbicznych" głębin świadomości.
Dźwięk rzeźbi ciało
Mowa kieruje więc postawę podmiotu w określonym kierunku. Im lepsza jest jakość mowy — to znaczy słuchania, gdyż mowa zależy od słuchania — tym lepsza postawa. Możemy wyobrazić sobie ciało poddane rzeźbiarskiej pracy dźwięku, myśląc, że jest otoczone bodźcami i impulsami, które nieustannie pobudzają wszystkie jego punkty. Suma tych nacisków układa się w zintegrowany obraz ciała. Bardzo łatwo to odczuć, zanurzając się w wzburzonym akwenie. Przy dotyku fal lepiej postrzega się granicę ciała.
Naturalnie istnieją strefy uprzywilejowane, bardziej wrażliwe na dźwięk i mowę: twarz, przednia powierzchnia tułowia i brzucha, grzbietowa powierzchnia prawej dłoni między kciukiem a wskazicielem, wewnętrzna część kończyn dolnych (zwłaszcza na poziomie kolana), podeszwy stóp. Są to strefy powierzchni ciała o największej gęstości włókien nerwowych wyspecjalizowanych w postrzeganiu bodźców uciskowych. Staje się więc jaśniejsze, że pionowość jest konieczna, by ofiarować jak największą powierzchnię bodźcom dźwiękowym — jeśli chce się rozwijać mowę. Według Tomatisa postawa pionowa nie byłaby jednak najlepsza w tym celu w sposób bezwzględny; istnieje inna, pochodzenia wschodniego — mianowicie asana lotosu w dyscyplinie jogi, która (zbieg okoliczności?) pozwala na lepsze wystawienie wyżej opisanych stref ciała na bodźce akustyczne.
Interesujące jest zauważyć, że własny obraz ciała można narzucić drugiej osobie — bardziej lub mniej świadomie. Tomatis opowiada w tym kontekście doświadczenie z RPA, z osobą jąkającą się. Niezwykle błyskotliwy człowiek dotknięty silnym jąkaniem, z towarzyszącymi mu chaotycznymi ruchami. W krótkim czasie, podczas konsultacji, w której uczestniczyły inne osoby, wszyscy poruszali się jak on — tymi samymi gestami. Najbardziej zdumionym był tłumacz, który był najmocniej zaangażowany w mowę tego podmiotu. Jego obraz ciała był tak silny, że podczas konsultacji narzucił go wszystkim. Tak dzieje się, gdy osobowość jest silna. Podobnie dobry śpiewak nas euforyzuje: w krótkim czasie czujemy się, jakbyśmy sami śpiewali; oddech się rozszerza, twarz się odpręża. W obecności miernych śpiewaków zaczynamy cierpieć — bo zaczynamy postępować jak oni: napieramy na krtań, zaciskając gardło. W tych perspektywach dialog zachodzi, gdy dwie osoby wprawiają się wzajemnie w wibrację. Według Tomatisa to, co pragniemy pierwotnie przekazać, to nie są ani maniery, ani dźwięki, lecz sensacje głęboko odczuwane, głęboko przeżywane w nas przez nasze neurony sensoryczne. To, co pragniemy zakomunikować, to wrażenia dotykowe, jakie słowo wywołuje na naszym klawiszu sensorycznym. Nieświadomie przekazujemy te same akordy naszemu rozmówcy, który nieświadomie uruchamia własny klawisz na obraz naszego — i wchodzimy w rezonans.
Eksperymentalną weryfikację zgodności obrazów ciała można uzyskać, narzucając dwóm podmiotom identyczne krzywe słuchowe i wprowadzając ich w sporną dyskusję: bardzo trudno wejdą w niezgodę. Następnie odwraca się krzywe i podejmuje bardzo trywialny dialog: bardzo łatwo, w ciągu kilku minut, dwie osoby zaczną się kłócić. Pokazuje to, jak bardzo umysł podlega wpływowi ciała — i jak bardzo to ciało z kolei modyfikuje mowę, przez którą jest rzeźbione. Interakcja umysł–ciało jest więc wzajemna. Która z dwóch stron jest źródłem procesu interakcji, trudno powiedzieć.
Postawa etno-językowa
Innym bardzo ważnym czynnikiem wpływającym na obraz ciała jest to, co Tomatis nazywa impedancją akustyczną środowiska. Tak nazywa się ogół minimalnych oporów, jakie środowisko stawia rozchodzeniu się dźwięku. Każde medium, przez które wędruje dźwięk, stawia mu pewien opór — sprzyjając lub nie jego przejściu, wzmacniając lub osłabiając jego natężenie na pewnych częstotliwościach. Otóż powietrze jest głównym medium przekazywania dźwięku. Głos, dźwięk instrumentu, szmer — zanim dotrze do ucha odbiorcy, przechodzą przez warstwę powietrza mniej lub bardziej grubą, w zależności od odległości między emitującym a odbierającym. Powietrze jednak nie jest takie samo wszędzie na świecie, ani nawet w obrębie tego samego kraju. Liczne czynniki geograficzne, klimatyczne, środowiskowe wpływają na konsystencję powietrza w sposób różny — w różnych punktach powierzchni Ziemi. Tomatis przemierzał świat długo z bardzo prostą aparaturą złożoną z mikrofonu połączonego z rejestratorem oraz głośnikiem nadającym te same dźwięki na ustalonej odległości. Analizując te same dźwięki emitowane przez głośnik w różnych strefach geograficznych — dzięki analizatorom panoramicznym rozkładającym dźwięki na rozmaite składowe częstotliwości — okazało się oczywiste, że ten sam dźwięk, w zależności od miejsca, w którym był nagrywany, był bogatszy w pewne częstotliwości niż inne. Mógł być w pewnym miejscu bogatszy w wysokie częstotliwości, w innym — w niskie itd. W przestrzeni między głośnikiem a mikrofonem jedyną rzeczą, jaka zmieniała się z miejsca na miejsce, było powietrze. By to potwierdzić, Tomatis przeanalizował obszerną próbę głosów osób z tych samych miejsc, w których nagrywał dźwięk z głośnika. Odpowiedniość częstotliwości była zdumiewająca; udało się określić strefy językowe, które nie miały nic wspólnego z granicami społeczno-geograficznymi. Można było zbudować dość szczegółową akustyczną geografię różnych stref geograficznych. Zanurzone w szczególnej kąpieli akustycznej, ucho zaczyna preferować częstotliwości najlepiej odbierane w tej strefie — a w konsekwencji wpływa to na fonację. Oczywiście, czynniki dziedziczne, kulturowe i socjologiczne należy brać pod uwagę; wpływ kryteriów akustycznych pozostaje jednak znaczny.
Kilka wieków temu emigrant angielski osiadł na kontynencie amerykańskim, gdzie powietrze wibruje bardziej przy 1500 hercach — częstotliwości, którą może usłyszeć, ale która wywołuje u niego sensacje różne od tych, do których przywykł.
Stopniowo jego percepcja się zmieniła, a wraz z nią cały jego głęboki system odpowiedzi słuchowych i kontrreakcji neuronalnych. Nabył innej postawy, innego usposobienia — swoistego dla nowej etniczności. Zmodyfikował swoje zachowanie, przyjął niezwykłe podejście psychologiczne. Te nowe warunki zmusiły ciało, by przystosowało się do nowego wszechświata akustycznego. Napięcie błony bębenkowej nie jest już to samo. Układ nerwowy, by być w zgodzie ze ślimakiem, musi zmodyfikować swoje funkcjonowanie. Z kolei część ucha środkowego — w szczególności mięsień strzemiączka — musi zmienić swoją modalność operacyjną. Pozostając pod kontrolą nerwu twarzowego, mięśnie twarzy poddawane są niezwykłej gimnastyce. Mięsień młoteczka, unerwiony tym samym nerwem, który kieruje żuchwą, również obiera położenia dostosowane do tej nowej operatywności. Rysy doznają w konsekwencji powolnego, lecz nieubłaganego fizjologicznego liftingu.
Parametry języków
W wyniku wyżej wymienionych analiz i innych studiów nad mową Tomatis identyfikuje cztery parametry pozwalające lepiej zrozumieć fantastyczny świat języków żywych. Te cztery kryteria, które możemy określić jako cechy charakterystyczne języka, to: pasmo przenoszenia, krzywa obwiedni w obrębie pasma przenoszenia, czas latencji oraz czas przygotowania ucha środkowego, czyli precesja.
Pasmo przenoszenia
Słuch ludzki rozwija się na spektrum dźwiękowym od dźwięków niskich do wysokich — od 16 herców aż do około 16 000–20 000 herców. Tymczasem w tym szerokim spektrum 11 oktaw nie wszystkie częstotliwości są odbierane w ten sam sposób. W każdym języku istnieją strefy preferencyjne — pasma przenoszenia — w obrębie których dźwięki są odbierane z większą ostrością. Przyczyną jest impedancja akustyczna miejsc i środowisk. Wiemy, że mówi się zupełnie inną barwą, gdy jest się w pokoju o pogłosie, niż w pokoju głuchym.
„Na kontynencie amerykańskim — mówi Tomatis — mieszkańcy nie nazalizują dla przyjemności. Dawni emigranci angielscy lub holenderscy z pewnością nie zachwycili się językami amerykańskich Indian — charakteryzującymi się tą fonetyczną osobliwością. To nie język amerykański skłania do nazalizacji. To »powietrze miejsca«, akustycznie bogatsze między 1000 a 2000 herców, zmusza ucho do przyjęcia swoistego pasma przenoszenia nazalizacji". Równolegle język francuski, używający preferencyjnie częstotliwości między 1000 a 2000 herców, ze strefą maksymalnej wrażliwości przy 1500 Hz, również prezentuje nazalizację w swojej fonetyce.
Krzywa obwiedni
Poprzez studium łańcucha wypowiadanej mowy za pomocą analizatorów panoramicznych i sonografów — aparatów zdolnych rozłożyć dźwięki tak, jak pryzmat rozkłada światło na barwy — udało się zwizualizować rozmaite częstotliwości, respektując ilościowo wartości względne każdej z nich, oraz wskazać różne części zdania — pod kątem częstotliwości, natężenia i długości trwania. Na uzyskanych w ten sposób fonogramach i sonogramach udało się znaleźć krzywe obwiedni średnich wartości częstotliwości napotykanych w analizie zdań zebranych w jednej grupie etnicznej.
Kilka przykładów z głównymi językami europejskimi może rozjaśnić to pojęcie. Diagramy tych krzywych Tomatis nazwał etnogramami i pokazują one — dla każdej grupy etno-językowej — strefy częstotliwościowe największej wrażliwości słuchowej. Na osi odciętych wskazane są częstotliwości, na osi rzędnych — natężenia.
Czas latencji
Otworzyć drzwi, chwycić coś, podrapać się… zakłada stan przewidywania, czas przygotowania, zwany latencją. Gdy postanawia się na coś spojrzeć, przygotowuje się widzenie, ustawia się przedmiot ostro. Zanim połączy się obrazy obu oczu, zanim doskonale się ustawi ostrość — ustanawia się czas latencji.
W przypadku ucha chodzi o czas niezbędny, by postawić się w słuchaniu. Z jednego końca globu na drugi nie nadstawiamy ucha w ten sam sposób. To zjawisko, które Tomatis nazwał czasem latencji lub opóźnieniem, różni się w zależności od stref geograficznych, lecz także od wieku. Wiele dzieci doprowadza rodziców do irytacji, zmuszając ich do powtarzania dwa-trzy razy tego samego zdania. Ich ucho nie osiągnęło jeszcze rytmu rozpoznawania językowego dorosłych. Mają czas latencji dłuższy od naszego. Reklamodawcy dobrze znają to zjawisko. W swoich planach reklamowych uwzględniają liczbę plakatów wieszanych na ścianach lub częstotliwość spotów telewizyjnych. Wiedzą, że ich wpływ zmienia się w zależności od tych parametrów.
Gdy zaczyna się mówić i przygotowuje się do słuchania siebie — bo każdy z nas jest pierwszym słuchaczem swojego własnego dyskursu — wprowadza się między nami a naszą mową wymiar, przygotowanie doskonale mierzalne, oddziałujące na przepływ słowny i akcentowanie. Czas latencji jest znaczący w piosenkach, w pieśniach ludowych, w sposobach opowiadania historii. Te produkty tradycji niosą bowiem rytm prelingwistyczny języka, na którym zaczepia się semantyka. Tomatis mówi, że dla większości naszych współczesnych fakt, że słuchanie zależy od postawy ciała, wydaje się rzeczą niezrozumiałą. Zapomina się jednak, że ucho nie ogranicza się do odszyfrowywania dźwięków tak, jak czyniłaby to głowica odczytu magnetofonu. Dysponuje aparatem — przedsionkiem — który skłania podmiot do umieszczenia ciała w określonej pozycji, by móc odpowiedzieć. Przedsionek jest siedzibą równowagi, ale od niego zależą również napięcie mięśni, ich siła względna, a przede wszystkim świadomość obrazu ciała. Długi czas latencji — jak czas słowiański — wzmacnia obraz ciała. Pozwala ponadto na precyzyjniejszą analizę dźwięków — dzięki wydłużeniu czasu przygotowania.
Być może nieprzypadkowo wielu specjalistów fonetyki jest pochodzenia słowiańskiego.
Tomatisowi udało się zmierzyć czasy latencji wielu języków i stwierdzić, jak ważnym elementem różnicującym je jest ten parametr.
Dziś wiemy na przykład, że Anglicy i Hiszpanie dzielą prymat językowej szybkości — 5 milisekund. Ten wyczyn jest łatwy dla Hiszpanów, którzy mówią bardzo blisko podstawowych dźwięków krtaniowych. Dla Anglików staje się on prawdziwym tour de force — ze względu na wysokie pasmo przenoszenia, które zmusza ich do mówienia czubkiem języka, więcej niż piętnaście centymetrów od krtani.
Czas precesji
Ostatni parametr brany pod uwagę w badaniach psycholingwistycznych Tomatisa dotyczy procesu integracji audio-cielesnej zwanego czasem precesji. Chodzi mianowicie o precesję, jaką wykazuje przewodnictwo kostne w stosunku do przewodnictwa powietrznego, i odpowiada ona czasowi niezbędnemu uchu środkowemu na zsynchronizowanie napięcia bębenkowego z dźwiękiem już odebranym drogą kostną. Zmienia się on z języka na język i od niego zależy odmienny sposób reagowania na różne rejestry językowe — każąc ciału przyjmować różne postawy, by lepiej z nimi się synchronizować.
Geografia akustyczna
Język francuski
W przypadku francuskiego można zauważyć, że strefy częstotliwościowe największego użytku sytuują się — jedna między 100 a 300 herców (czyli w niskich), druga w wysokich, między 1000 a 2000 Hz, z punktem największej wrażliwości przy 1500 Hz. Różnica natężenia dźwiękowego między tymi dwiema strefami wynosi około 20 decybeli. Pic przy 1500 Hz, ze względnym opadnięciem ku wysokim, tłumaczy występowanie nazalizacji w tym języku. To pasmo przenoszenia, w połączeniu z czasem latencji 50 milisekund, czyni francuski językiem hiper-wokalnym o słabym akcencie tonicznym. Aby dać przykład: osoba francuska wymawia słowo „Bonjour" po francusku. Usłyszymy liniowy ślizg składający się w pierwszej części z małego „b" i wielkiego „ON", a w drugiej z małego „j" i wielkiego „OUR". Przeciwnie, jeśli to amerykański rodzimy użytkownik wymawia to samo słowo, otrzymamy hiper-spółgłoskową wymowę typową dla amerykańskiego: Bon-Jour z wielkim „B", małym „on", wielkim „J" i małym „our". Francuski używa ponadto strefy częstotliwości typowej dla mowy. Mogłoby to wyjaśniać, częściowo, wagę, jaką sama mowa zajmuje w kulturze francuskiej.
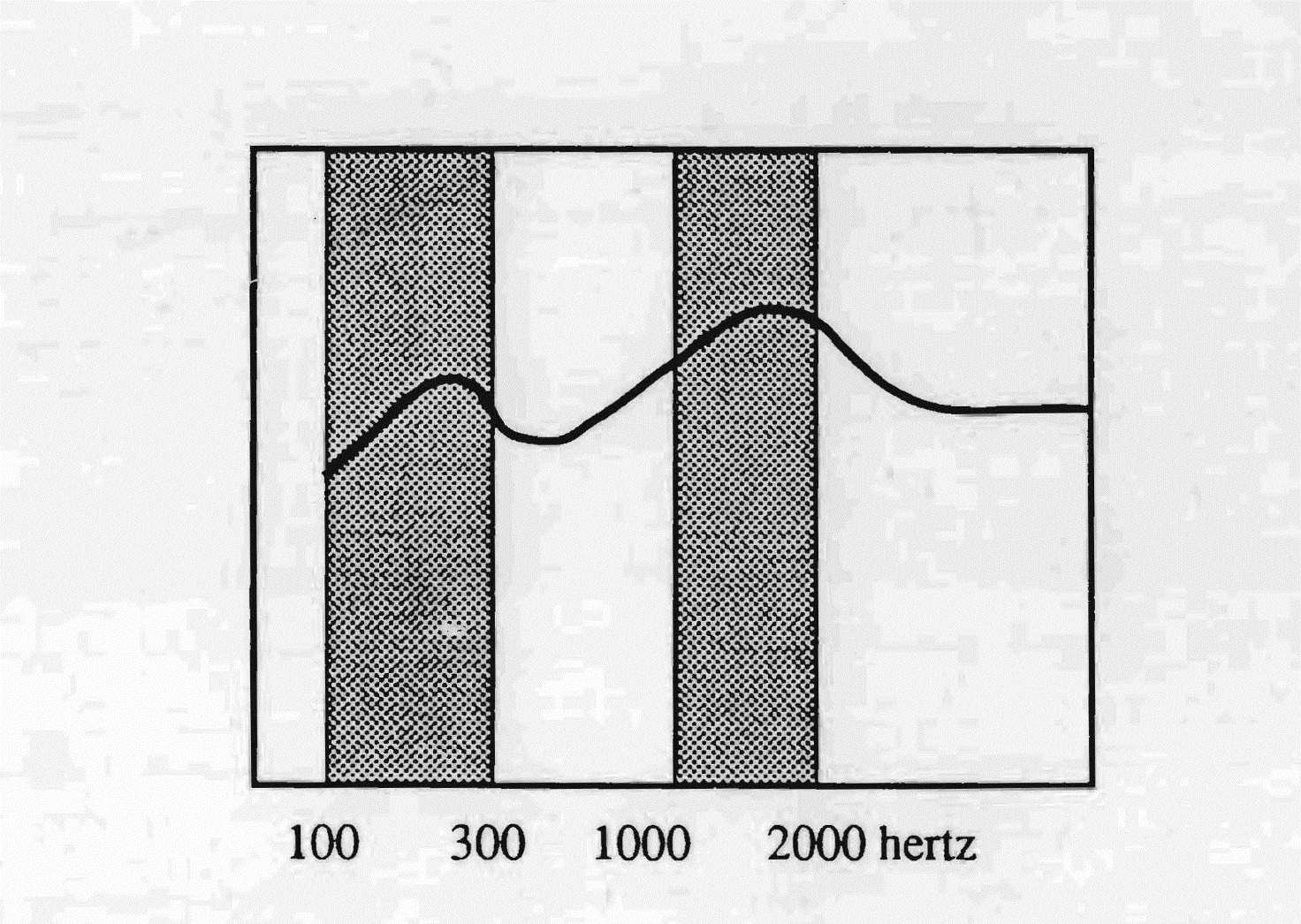
Język francuski używa częstotliwości od 100 do 300 Hz oraz od 1000 do 2000 Hz.
Język angielski
Zasadniczą cechą angielskiego typu słuchu jest wielka wrażliwość na dźwięki wysokie oraz bardzo szybki czas latencji — wpływające: drugi na czas emisji sylab, pierwszy na obraz ciała skoncentrowany w górnej części ciała.
Mowa oczywiście o angielskim mówionym w Anglii. Od 2000 Hz krzywa kreśli wstępującą o ok. 6 decybeli na oktawę, ciągnącą się aż do 12 000 herców i nawet powyżej — co nadaje temu typowi słuchu krzywą odpowiedzi przypominającą tę z obwodów wzmacniaczy wysokiej wierności. Konsekwencją jest bogactwo sybilantów w tym języku.
W angielskim potoku słownym przyciąganie ku wysokim całości schematu głosowego tłumaczy, przez słuchową kontrreakcję, systematyczną dyftongizację samogłosek. Te, choć istnieją w spektrum wyjściowym, prześlizgują się od dźwięku podstawowego ku pasmu częstotliwości powyżej 2000 Hz. Pasmo wysokie odbierane przez ucho angielskie narzuca bowiem, przez kontrreakcję audio-głosową, taką strukturę, że dźwięk podstawowy — znajdujący się w niskich z powodu ograniczonych możliwości krtani (300 herców) — nie może być utrzymany w emisji początkowej, nie będąc selekcjonowanym przez ucho. W konsekwencji dochodzi do ślizgu ku wysokim, tworzącego dyftongizację. Interesujące jest zauważyć, że odległość istniejąca między dźwiękiem podstawowym — pierwotnie tym samym we wszystkich językach i zawsze niskim — a pasmem przenoszenia języka tłumaczy mniej lub bardziej dużą różnicę między pisemnym zapisem języka a jego wymową. Modyfikacja ta jest tym ważniejsza, im większa różnica. Na przykład hiszpański, ustawiony głównie na dźwiękach niskich, pisze się praktycznie tak, jak się go wymawia, podczas gdy angielski wykazuje maksimum zniekształceń między językiem mówionym a jego zapisem pisemnym. Porównując pasmo słuchowe angielskie z francuskim, zauważa się, że jedno używa częstotliwości nieselekcjonowanych przez drugie i odwrotnie. Wiadomo dobrze, że dla ucha francuskiego trudno jest odbierać angielski i odwrotnie. Język amerykański, używający niższego pasma przenoszenia niż angielski brytyjski, z punktem maksymalnej wrażliwości przy 1500 herców, jest lepiej odbierany przez ucho francuskie niż angielski oksfordzki.
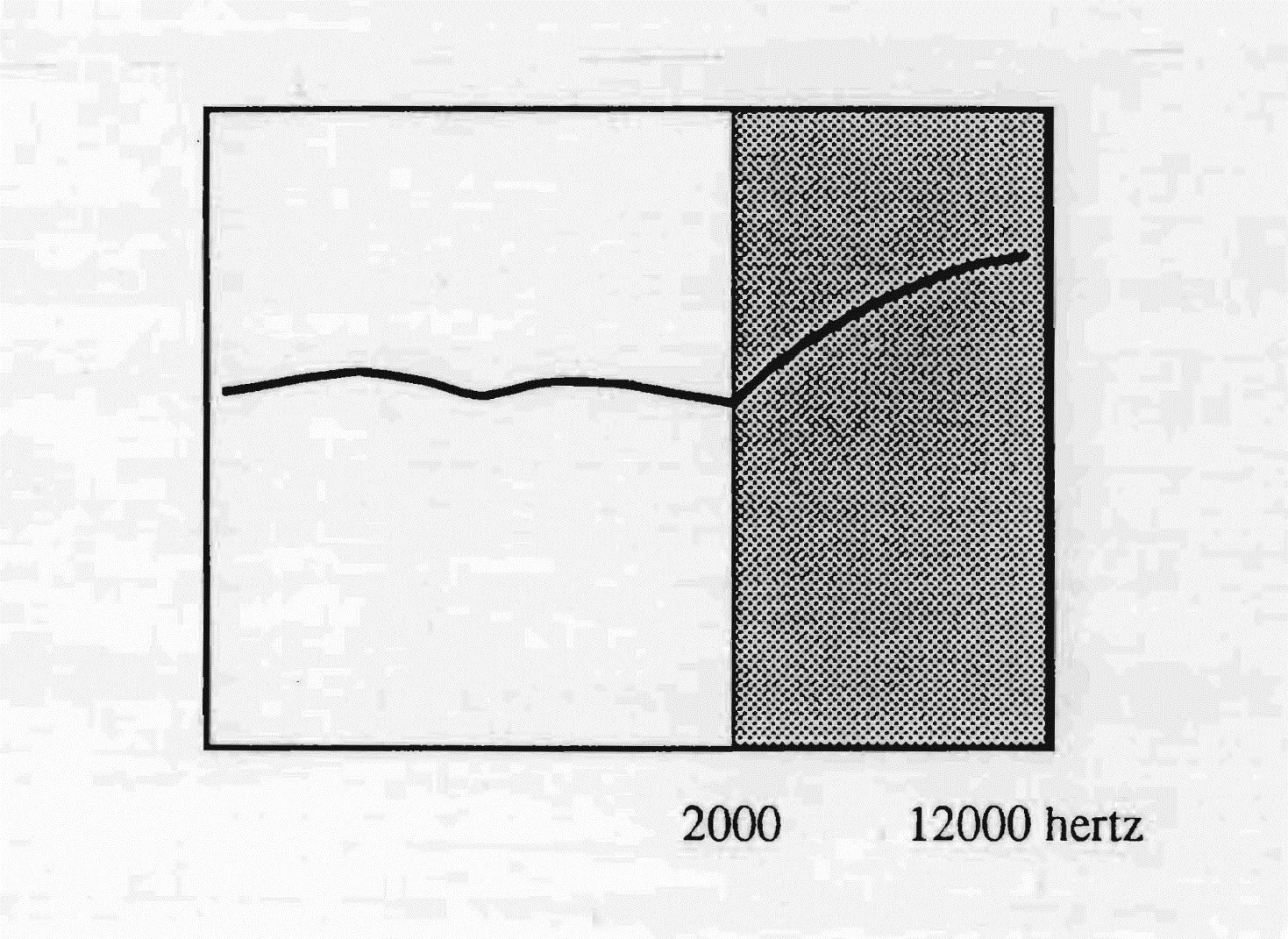
Język angielski używa częstotliwości od 2000 do 12 000 Hz, z największą wrażliwością w bardzo wysokich.
Język niemiecki
Pasmo przenoszenia języka niemieckiego sięga od niskich aż do 3000 herców. Wrażliwość jest najsilniejsza między 250 a 2000 herców, ze szczytem największej przepustowości około 800 herców. Szerokość tego pasma pozwala łatwo integrować fonemy należące do innych języków — pod warunkiem, że mieszczą się one w jego terytorium częstotliwościowym.
Do tego szerokiego pasma dochodzi bardzo ważna cecha ucha niemieckiego: stosunkowo długi czas latencji. Implikuje to silne pchnięcie krtani i znaczne zaangażowanie ciała podczas fonacji — niezbędne do podtrzymania krtaniowego pchnięcia, charakterystycznego dla tej grupy językowej.
Ważne jest zauważyć, że aby słuchać i mówić w danym języku, trzeba ustawić się w postawie, jaką on narzuca. To parametry akustyczne — pasmo przenoszenia, krzywa obwiedni, latencja i precesja — narzucają postawę i postawę motoryczną, dzięki stałemu dialogowi między ślimakiem a przedsionkiem. Na przykład, by słuchać i mówić po niemiecku, trzeba trzymać się szczególnie prosto, mieć dobrze otwartą klatkę piersiową i być dobrze osadzonym na nogach. Postawa cielesna, która ma niewiele wspólnego z postawą Anglika czy Hiszpana.
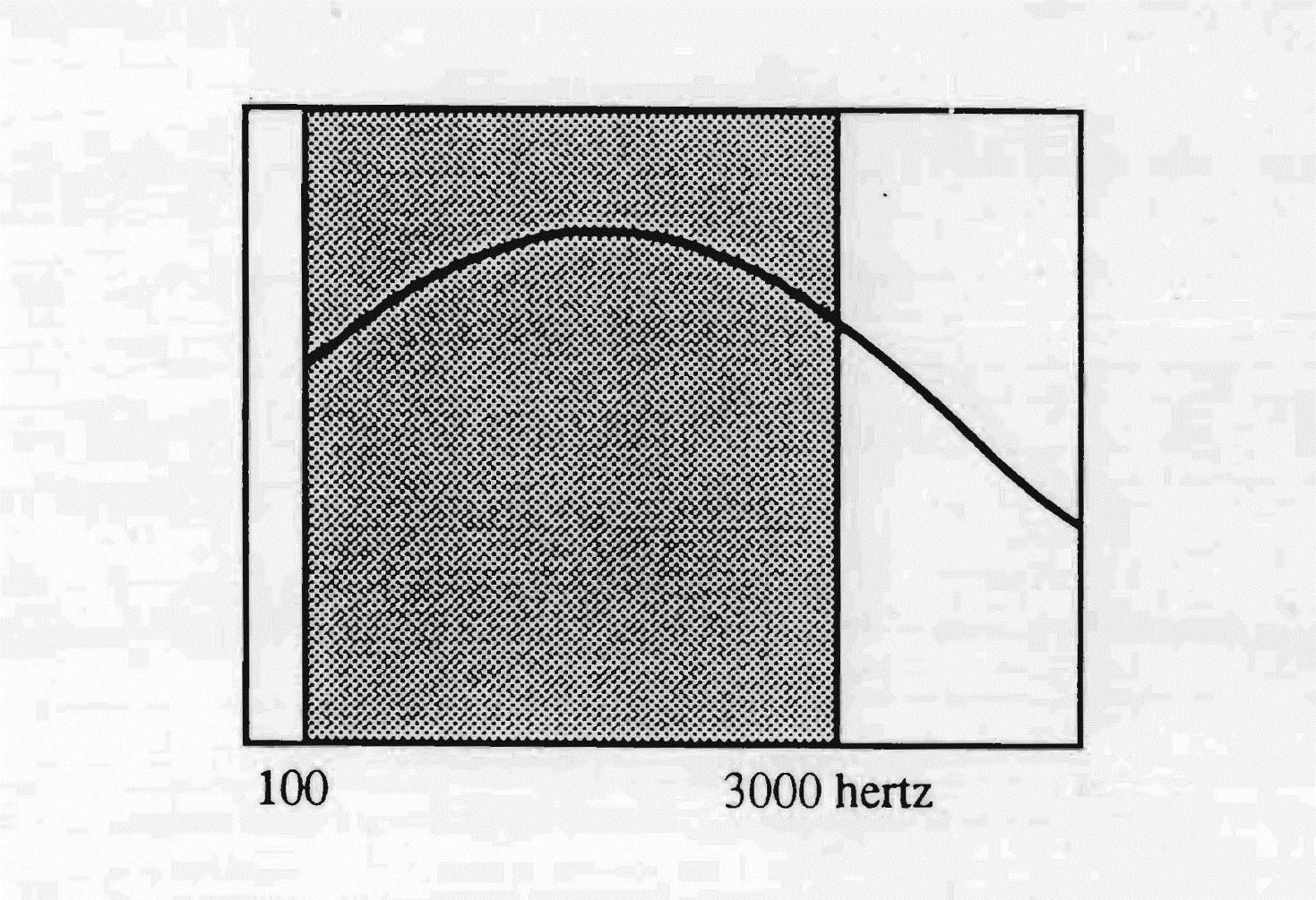
Język niemiecki używa częstotliwości od 100 do 3000 Hz, z największą wrażliwością około 750 Hz.
Język hiszpański
Cechą hiszpańskiego typu słuchu jest wielka wrażliwość na dźwięki niskie, na paśmie sięgającym do 500 herców, oraz mniejszy poziom natężenia w innej strefie — od 1500 do 2500 herców — z bardzo zmniejszoną wrażliwością w wysokich.
Szczyt przy 250 herców wprowadza w reakcji audio-głosowej jotę, podczas gdy brak przepustowości w wysokich powyżej 2500 herców tłumaczy ciężkość hiszpańskich sybilantów: ślizg na przykład „f" w przydechową „h". Oczywiste, na podstawie wykresu, że przeciętny Hiszpan napotyka trudność w integrowaniu języków obcych. Przeważające użycie częstotliwości niskich w języku kastylijskim sprzyja obrazowi ciała inwestowanemu mocno w miednicę i nogi.
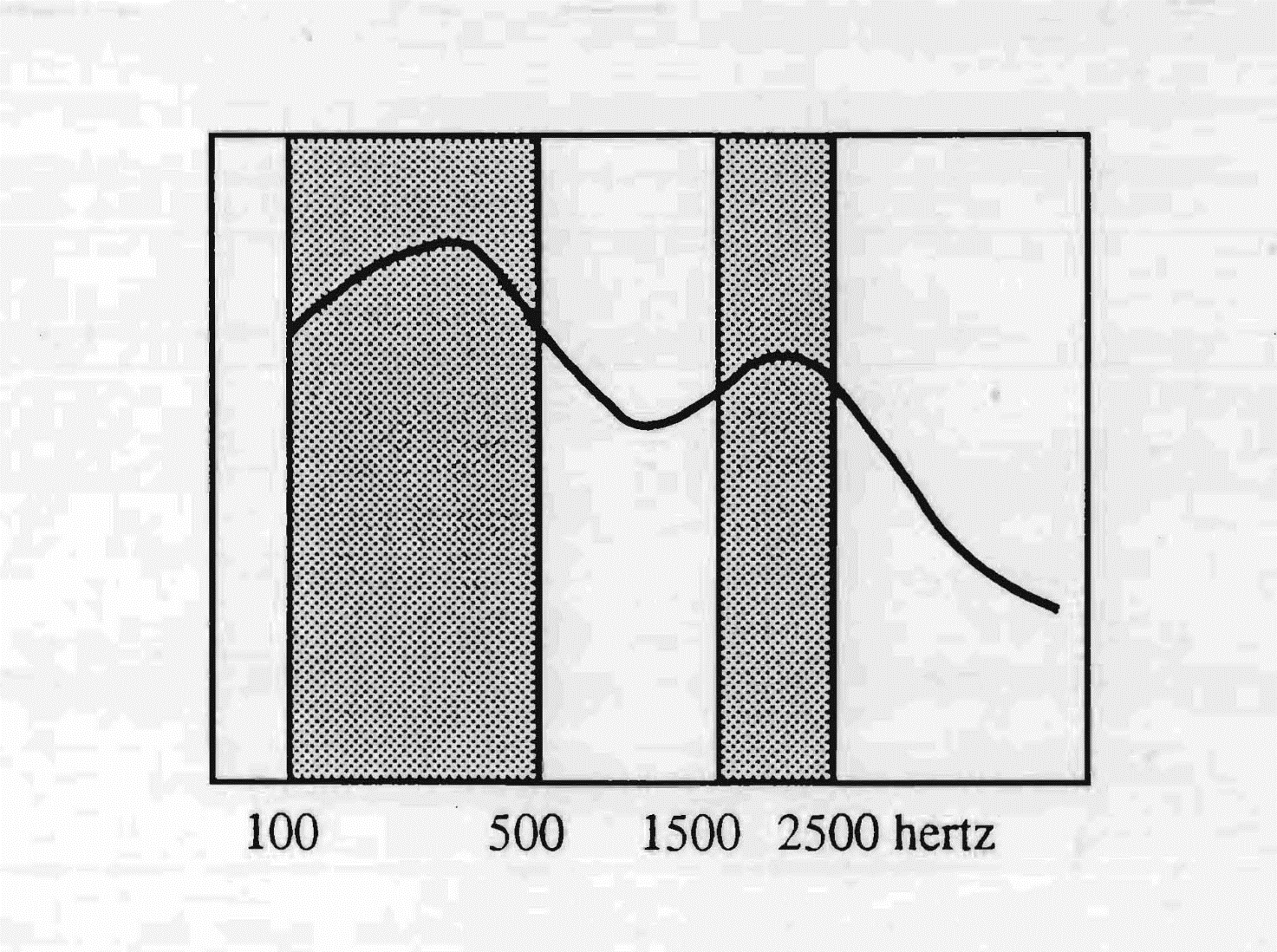
Pasmo przenoszenia hiszpańskiego kastylijskiego sięga od 100 do 500 Hz oraz od 1500 do 2500 Hz. Hiszpański typ słuchu jest bardziej wrażliwy na dźwięki niskie, gdzie głos jest silniejszy. Słaba wrażliwość na wysokie tłumaczy brak sybilantów w tym języku.
Język arabski
Język arabski natomiast charakteryzuje się pasmem przenoszenia bardzo bliskim hiszpańskiemu kastylijskiemu i czasem latencji typu niemieckiego. Stąd brak sybilantów jak w hiszpańskim oraz silne pchnięcie krtani typowe dla użytkowników niemieckiego.
Języki słowiańskie
Rosjanie i Słowianie w ogólności dysponują bardzo rozległym otwarciem przepony słuchowej — od dźwięków niskich aż do najwyższych — z silniejszym powinowactwem ku tonom niskim. To selektywne bogactwo — w przeciwieństwie do francuskiego — pozwala doskonale postrzegać fonemy innych języków.
Audio-postularny odruch słowiańskiej grupy językowej charakteryzuje się sposobem trzymania się dobrze osadzonym w ziemi, amplitudą oddechu, sposobem emitowania dźwięków szerokich i ciepłych — znaku silnej integracji cielesnej. Ta z kolei zależy zarówno od szerokiego pasma przenoszenia, jak i od czasu latencji percepcji — wystarczająco długiego, by sprzyjać silnemu objęciu dźwięku przez ciało.
Interesujące zauważyć, że każda grupa etno-językowa ma postawę swojej mowy — konsekwencję jej sposobu słuchania.
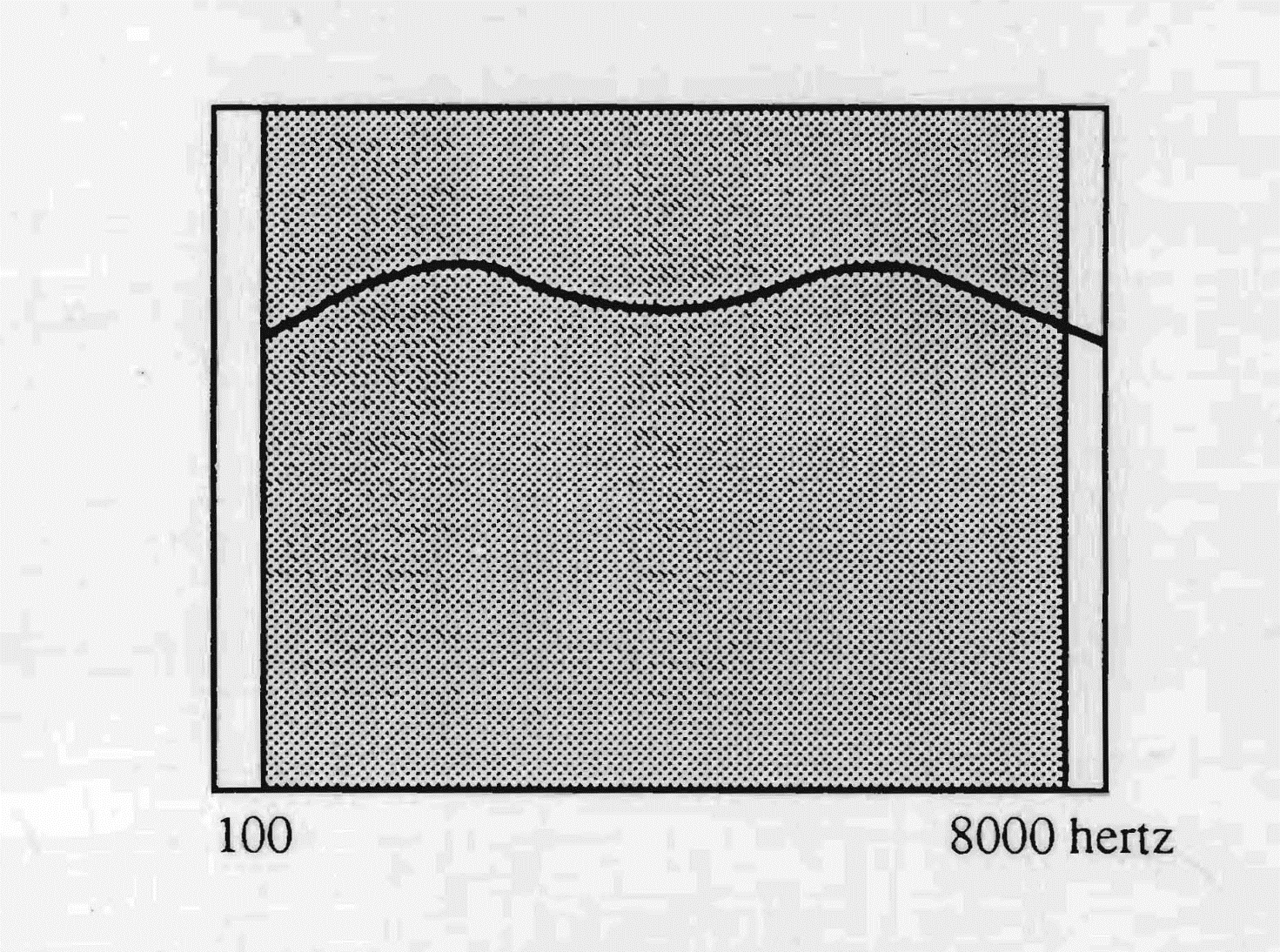
Pasma przenoszenia języków słowiańskich obejmują niemal wszystkie częstotliwości używane przez ucho ludzkie. Stąd łatwość, z jaką ich użytkownicy uczą się innych języków.
Język portugalski
Język portugalski — ten mówiony w Portugalii — prezentuje cechy języków słowiańskich (pasmo przenoszenia, opóźnienie i precesja). Brzmi jak hiszpański autokontrolowany przez ucho typu słowiańskiego. Eksperymentalnie zabawne jest sprawdzenie tego faktu, przepuszczając zdanie portugalskie przez filtry, których krzywa odpowiedzi odpowiada uchu hiszpańskiemu. Dla tego, kto rozumie hiszpański, portugalski staje się tak łatwiej zrozumiały.
Język włoski
Krzywa obwiedni języka włoskiego, w połączeniu ze szczególną strefą częstotliwości pokrywaną jego pasmem przenoszenia oraz właściwymi mu czasami latencji, wskazuje na ucho bardzo muzykalne.
Pasmo przenoszenia, choć niezbyt rozległe — od 2000 do 4000 Hz — dotyka strefy częstotliwości bardzo sprzyjającej śpiewowi. Mówiąc o włoskim, często powiada się, że to język muzyczny. Nie przypadkiem śpiew operowy narodził się właśnie tu. Między 2000 a 4000 Hz układ kostny ma największy rezonans, a dźwięk kostny to ten, który śpiewak operowy wydaje, gdy śpiewa z jakością.
To bowiem krtań, wibrując o kręgi szyjne, wprawia w rezonans całą strukturę szkieletową — bardzo wrażliwą na dźwięki wysokie — wytwarzając charakterystyczny dźwięk włoskiego sposobu śpiewania. Wszystko to sprzyjane jest przez audio-posturalną reakcję związaną z włoskim typem słuchania.
Muzykalność słuchania — a więc i fonacji — typu włoskiego sprzyjana jest również wstępowaniem krzywej obwiedni, która rośnie od niskich ku wysokim z nachyleniem ok. 6 decybeli na oktawę aż do 3000–4000 herców, po czym lekko opada ku skrajnym wysokim.
Dla Tomatisa ten typ krzywej jest bardzo bliski temu, co nazywa idealnym słuchaniem muzycznym. Czasy latencji (75 milisekund) i przygotowania (150 milisekund) typowe dla włoskiego wpływają na czas emisji sylab i sprzyjają wymowie spółgłosek i samogłosek w juxtapozycji — nadając językowi jego wyrafinowanie muzyczny rytm. „Świetlistość" dźwięków języka pochodzi z jego pasma przenoszenia ulokowanego w strefie melodii.
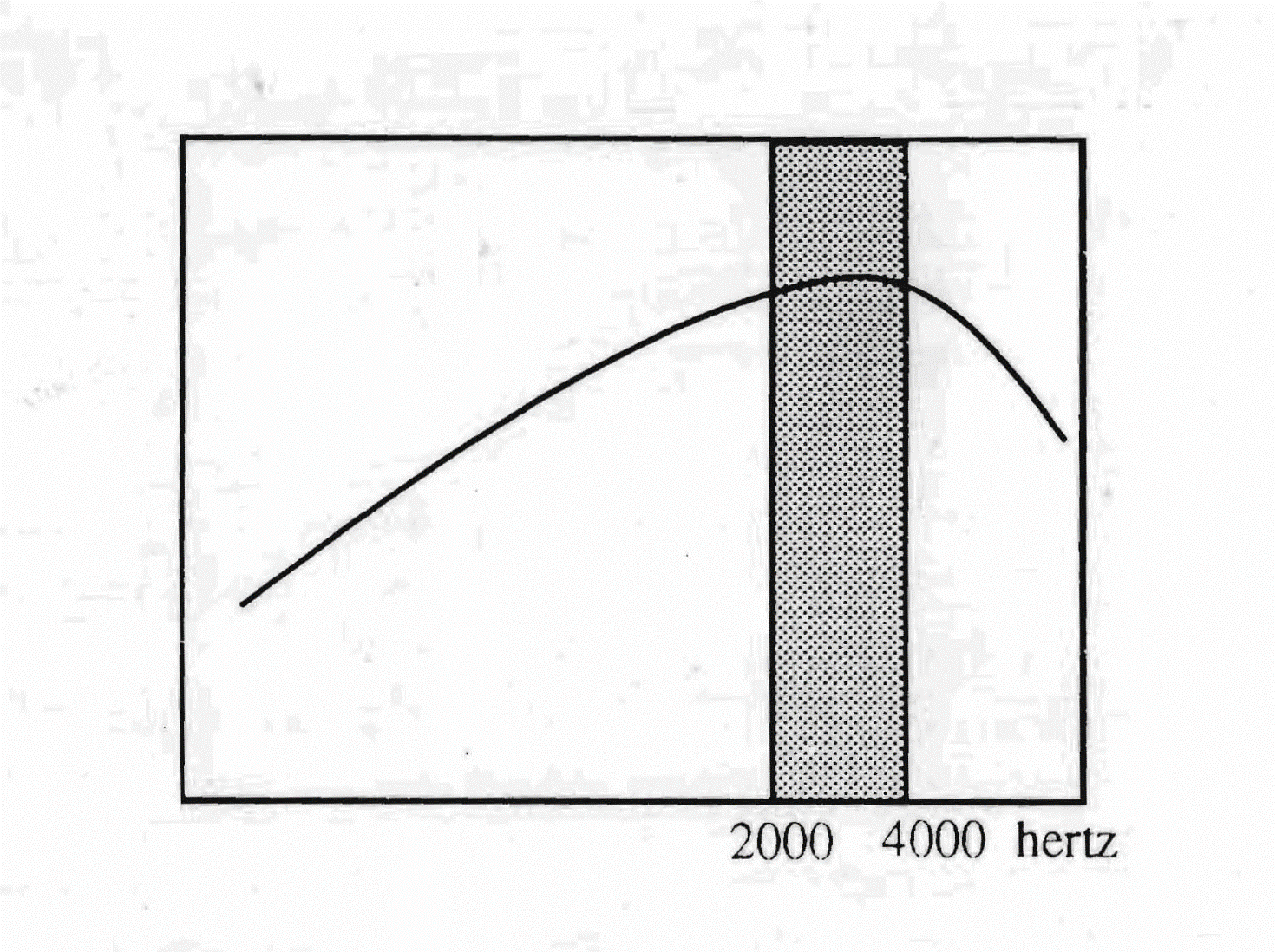
Pasmo przenoszenia języka włoskiego obejmuje zakres częstotliwości od 2000 do 4000 Hz. Wstępujący przebieg krzywej obwiedni — od niskich aż do 3000 herców — i lekka inflexja, jaka następuje w wysokich, dają słuchanie typu muzycznego.
Tekst oryginalny: Concetto Campo, opublikowany na tomatis.it.