Warunkowanie audio-głosowe (Akademia Medycyny 1960)
Komunikat Alfreda Tomatisa przedstawiony Narodowej Akademii Medycyny przez M. Moulonguet i opublikowany w Bulletin de l’Académie Nationale de Médecine (tom 144, nr 11 i 12, 1960, s. 197-200). W czterech gęstych stronach Tomatis przedstawia dyspozytyw eksperymentalny opracowany przez siebie od 1947 roku — mikrofony, wzmacniacz, filtry, bascule — by trwale warunkować fonację przez słyszenie, oraz jego zastosowanie w integracji języków obcych w laboratoriach językowych Centrum Audiowizualnego École Normale Supérieure w Saint-Cloud.
Warunkowanie audio-głosowe
autorstwa M. Alfreda Tomatisa
(Prezentacja dokonana przez M. Moulonguet)
Drukowane wraz z periodykiem Bulletin de l’Académie Nationale de Médecine — tom 144, nr 11 i 12, 1960, s. 197-200.
I. — Wstęp
Już w 1947 roku, uderzony stałym paralelizmem między badaniem audiometrycznym podmiotu a krzywą obwiedni analizy spektralnej jego głosu, podjąłem studium reakcji i kontrreakcji słuchu na emisję głosową.
Posłużyłem się wówczas dwoma elektronicznymi montażami:
Pierwszy pozwalał wizualizować rozkład harmoniczny emitowanych dźwięków;
Drugi dawał możliwość modyfikowania do woli słyszenia podmiotu poddanego doświadczeniu.
Podmiot mówił przed dwoma mikrofonami M1 i M2.
M1 pochwytywał dźwięk na rzecz rejestratora pozwalającego na późniejszą analizę spektralną dźwięku;
M2 atakował wzmacniacz, którego charakterystyki odpowiedzi na poziomie słuchawek były modyfikowalne do woli dzięki zestawowi filtrów (górnoprzepustowy, dolnoprzepustowy, środkowoprzepustowy), co pozwalało modyfikować dowolnie sposób słyszenia podmiotu poddanego doświadczeniu, a w razie potrzeby także jego sposób kontrolowania siebie.
Tak nadzwyczajna doniosłość wyłaniających się kontrreakcji pozwoliła mi stwierdzić, że mamy do czynienia z prawdziwym zamkniętym obwodem autoinformacji, którego czujnikiem kontrolnym podczas emisji na poziomie narządów fonacji nie jest niczym innym niż uchem — i że każda modyfikacja narzucona temu czujnikowi pociąga za sobą natychmiast znaczną modyfikację gestu głosowego, łatwą do wykrycia wzrokowo, słuchowo lub w każdym razie fizycznie kontrolowaną na lampie katodowej.
Tak więc już w 1954 roku mogłem stwierdzić, że „głos podmiotu zawiera tylko te harmoniczne, które jego ucho jest w stanie usłyszeć".
Następnie różni eksperymentatorzy potwierdzili te dane, a M. Raoul Husson — podejmując to studium w 1957 roku pod impulsem prof. Monniera w Laboratorium Fizjologii Funkcji na Sorbonie — pogrupował ten zespół audio-fonacyjnych kontrreakcji pod nazwą „efektu Tomatisa".
II. — Realizacja warunkowania audio-głosowego
Mając absolutną pewność, że tryb ekspresji głosowej właściwy danej misji — czyli warunkowaniu całego aparatu fonacyjnego uzewnętrzniającemu się w znanym geście głosowym — odpowiada sposobowi słyszenia wyznaczonemu mniej lub bardziej złożonym warunkowaniem całego aparatu słuchowego, i mając ponadto pewność, że każda modyfikacja tego sposobu słyszenia wywołuje modyfikację gestu fonacyjnego, podjąłem próbę uruchomienia warunkowania audio-głosowego, którego doniosłość terapeutyczna jest znaczna w dysfoniach, w edukacji głosowej, a nawet w samym poszukiwaniu estetyki głosowej.
[Ryc. 1 — Schemat dyspozytywu: słuchawki, mikrofony M1 i M2, rejestrator, analizator, wzmacniacz wyposażony w filtry górnoprzepustowy / dolnoprzepustowy / środkowoprzepustowy.]
[Ryc. 2 — Pętla regulacji audio-fonacyjnej: narządy fonacji ↔ czujnik słuchowy.]
Uruchomienie warunkowania zdolnego modyfikować emisję sprowadza się do zmuszenia ucha do słyszenia w pewien określony sposób emisji dźwięku. Innymi słowy, gest głosowy, który nazwiemy G1 i który prowadzi do emisji E1 złej jakości, odpowiada — jak wiemy — globalnemu słyszeniu A1. Skorygować gest G1, by zobaczyć, jak przemienia się w G2 — gest głosowy zdolny emitować dźwięki E2 wysokiej jakości — to wyłącznie zmusić ucho do użycia trybu akomodacji wyznaczającego sposób słyszenia dźwięków.
Wystarczy więc, by zatrzeć gest G1 i zobaczyć od tej chwili pojawienie się gestu G2, uwarunkować słyszenie do nowego trybu akomodacji częstotliwości emisji dźwięków.
Dla zrealizowania tego warunkowania od kilku lat używam następującego montażu:
Mikrofon M atakuje wzmacniacz, z którego wychodzą dwa różne obwody — obwody te tworzą dwa kanały, które nie funkcjonują jednocześnie.
[Ryc. 3 — Mikrofon M atakujący wzmacniacz, który zasila dwa kanały C1 i C2 przełączane przez bascule, wracające do słuchawek.]
Dla danego natężenia, modyfikowalnego do woli, kanał C1 pozostaje sam otwarty. Pozwala on podmiotowi poddanemu doświadczeniu słuchać siebie, co jest jego nawykiem. Jeśli zaś — choć podmiot niczego nie wie o zmianie — modyfikuje on emisję dźwięku ze swej strony, to z chwilą, gdy do nieustannie obecnego szumu otoczenia dodaje istotne natężenie przekraczające próg, kanał C1 się zamyka, a otwiera się jedynie kanał C2. Ten drugi kanał elektroniczny zmusi ucho do innego trybu kontroli, jaki wybraliśmy — trybu odpowiadającego w szczególności emisji pięknego głosu. Innymi słowy, otwarcie kanału C2 pozwala tylko słyszeć w sposób przypisany gestowi A2 i automatycznie przejść do sposobu słyszenia A2, właściwego pożądanemu gestowi G2.
Z chwilą zakończenia emisji głosowej zmniejszone natężenie sprawia, że system przełącza się w przeciwnym kierunku — i kanał C2 się zamyka, podczas gdy C1 się otwiera. Ta reguła powtarza się za każdym razem, gdy podmiot chce mówić, a warunkowanie pojawia się bardzo szybko. Już od pierwszych dni — po sesji półgodzinnej — pozostaje rezydualność około półgodzinna. Po około piętnastu dniach pozostaje ona stała.
Zresztą ta gra bascule może szybko stać się zjawiskiem świadomym i pozwolić — do woli — na słyszenie tak, jak się chce.
Aby następnie zmodyfikować rytm i intonację języka, zmieniłem czas włączenia bascule i — wyznaczywszy ponadto „słyszenia rasowe", czyli sposoby słyszenia — użyłem tej techniki do integracji języków obcych.
Faktycznie różne sposoby słyszenia charakteryzują się:
a) przez pasma przepustowe, dające aparatowi kontroli słuchowej swoiste krzywe odpowiedzi;
b) przez czas T potrzebny do osiągnięcia adaptacji słuchowej, która pozwala na realizację tej krzywej.
Integracja językowa okazuje się nadzwyczajnie szybka, a jej zastosowanie w Laboratoriach Języków Żywych w Centrum Audiowizualnym École Normale Supérieure w Saint-Cloud stanowi tego najważniejszy eksperymentalny dowód.
Źródło: Tomatis A., „Conditionnement audio-vocal" (prezentacja dokonana przez M. Moulonguet), Bulletin de l’Académie Nationale de Médecine, t. 144, nr 11 i 12, 1960, s. 197-200. Odbitka wydrukowana przez Masson et Cie, wydawcy, Paryż (depozyt prawny 1966, I kwartał, nr ref. 4357). Dokument zdigitalizowany pochodzący z osobistych archiwów Alfreda Tomatisa.
Dokument oryginalny — facsimile historycznego PDF (bezpośrednie pobranie).
Ryciny dokumentu oryginalnego
Schematy i ilustracje pochodzące z facsimile PDF oryginalnego artykułu.

Rycina 1 — facsimile s. 1
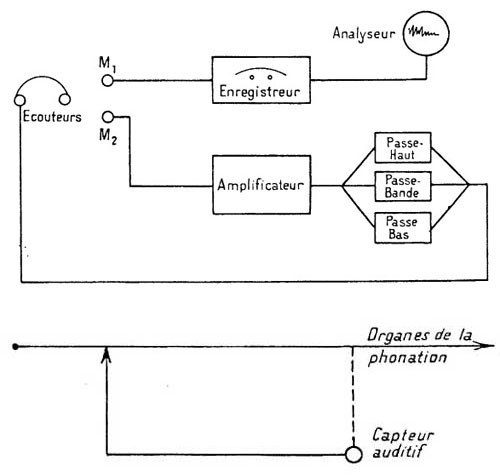
Rycina 2 — facsimile s. 2
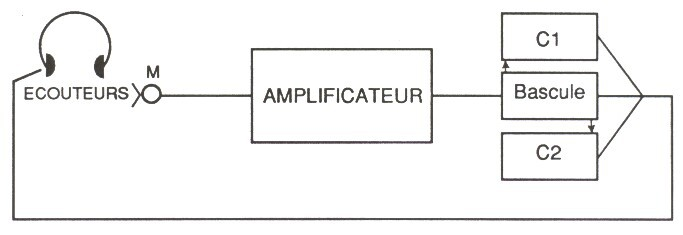
Rycina 3 — facsimile s. 3