I Fonemi in primo piano
Un poco di fonetica
In occasione di una messa a punto del lavoro ortofonico di un membro della rete, l’analisi sonografica di certi fonemi è stata realizzata dal Professor Tomatis nel suo laboratorio parigino.
Le differenziazioni fonetiche fanno incontestabilmente parte delle preoccupazioni professionali degli ortofonisti. Esse non sono, in effetti, che differenziazioni uditive di fronte a un suono, e a fortiori di fronte al linguaggio. Quest’ultimo è composto da una successione di suoni che determinano la catena parlata: concatenamento di lettere, di sillabe, di parole, che costituiscono la frase donde emerge il significato globale che sorge esso stesso dai valori semantici di ciascuno dei componenti verbali. La composizione del contesto accorda, in definitiva, il senso della struttura ingaggiata, sostenuta dal ritmo e dall’intonazione della colata verbale.
Significa quanto sia importante la partecipazione dell’audizione.
Ci sembra utile rammentare gli elementi essenziali che giocano nell’orecchio:
-
Anzitutto, allorché essa si presenta come dovrebbe essere, essa si dispiega, secondo la curva fisiologica (di Flechter), dai gravi verso gli acuti su uno spettro che va da 16 a 16000 periodi,
-
essa si profila su una curva che non presenta alcuna distorsione,
-
essa può, se s’ingaggia ad ascoltare, decomporre i suoni che le pervengono, tanto quelli della catena parlata quanto quelli della frase musicale. Diciamo di sfuggita che, su tale punto particolare, il linguaggio si costruisce, quanto a esso, su una musicalità specifica e caratteristica di ciascuno degli idiomi,
-
la selettività deve entrare in linea di conto. Essa è una qualità importante dell’orecchio che richiede alcune informazioni complementari, perché inabituale. Essa risponde alla possibilità che possiede l’orecchio di pervenire non soltanto a differenziare le altezze tonali ma altresì a distinguere il senso delle variazioni da un suono a un altro. È insomma il potere discriminativo frequenziale che caratterizza tale particolarità,
-
la lateralità uditiva è parimenti da analizzare ché essa gioca sul potere discriminativo sequenziale della frase,
-
è necessario rammentare che i linguaggi, quali che siano, devono adattarsi alle possibilità d’ascolto delle differenti etnie.
Non verrebbe in mente a nessuno di sostenere che il linguaggio orale possa trovare la propria origine in una società composta da sordomuti. Esso non ha potuto essere generato che da udenti, meglio ancora da ascoltanti, da veri «fonetisti». E ci si ricorda dell’asserzione di Daniel Jones nella sua opera «An outline of Phonetics» in cui precisa che non si poteva affatto pretendere d’essere un fonetista senza essere dotati di un orecchio perfetto. Insomma, di un orecchio rispondente alle caratteristiche che abbiamo or ora segnalato.
Per altro verso, le differenziazioni fonetiche «pertinenti», messe in evidenza dalla Scuola di Praga ed esplicitate da Troubetzkoy nella sua opera sulla «Fonologia» non fanno che definire i «canali linguistici» che non sono, in realtà, che «canali» uditivi.
La prova più flagrante è data dalle deformazioni fonetiche rilevate presso il bambino con importanti deficit d’audizione. In funzione della sede di questi ultimi nella scala dello spettro acustico, è agevole prevedere quali saranno i difetti di pronuncia. Una deficienza importante negli acuti è sicuramente un grosso svantaggio per integrare le sibilanti e, per via di conseguenza, per riprodurle spontaneamente.
Stando così le cose, è facile visualizzare il parallelismo che lega l’integrazione fonetica e la percezione uditiva. L’orecchio può assai bene essere assimilato a un filtro che assicura l’integrazione in funzione delle proprie potenzialità. Esso tradurrà così gli effetti provocati dai difetti delle sue curve di risposta, ancorché, in prima analisi, questi potessero apparire minori. È così che, persino se le deformazioni fonetiche sono poco rilevabili per un orecchio non avvertito, poco esperto insomma, esse si manifesteranno obbligatoriamente all’atto della messa in funzione dei processi più complessi come quelli della lettura e dell’ortografia.
Riprendiamo ora il lavoro propriamente detto degli studi sonografici di fonemi.
Commenti sui fonemi
Lo studio verte su fonemi della lingua francese. L’analizzatore adottato è il sonografo.
Quest’ultimo consente di mettere in evidenza:
-
Il tempo di sviluppo del fonema,
-
l’analisi frequenziale di tale fonema in funzione dello scorrere temporale,
-
l’intensità.
-
Il tempo s’inscrive sull’asse delle x,
-
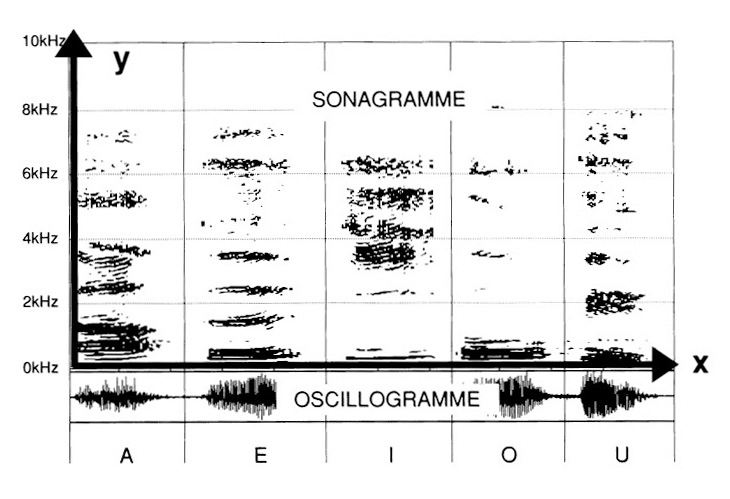
le frequenze sull’asse delle «y». L’analisi si fa qui sino a 10 kHz (vedi fig. 1)
-
l’intensità si legge in funzione della nerezza più o meno accusata del tratto frequenziale. Così, ciascuna frequenza si manifesta con la propria intensità relativa rispetto all’insieme.
Diversi suoni sono stati raccolti a titolo d’esempio. Beninteso, si può a piacere applicare ciò che presentiamo su un’ampia scala, ma gli elementi primordiali sono già messi in evidenza con i tracciati scelti.
(fig. 1)
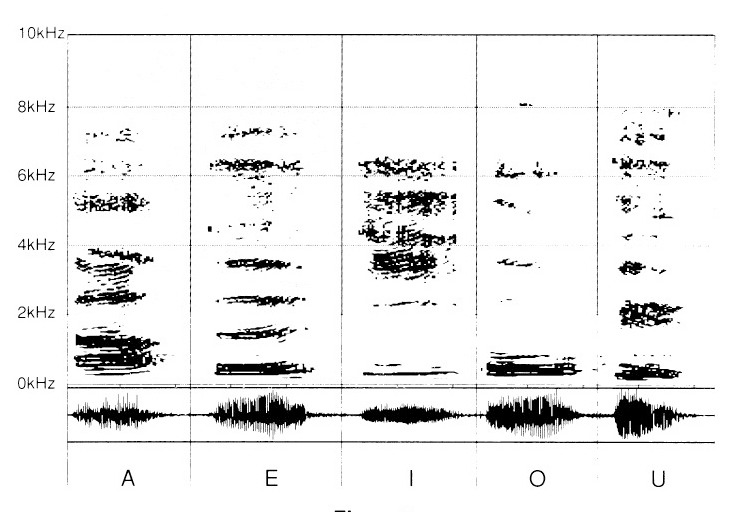
Anzitutto, sono registrate le vocali: «A», «E», «I», «O» e «U».
(fig. 2)
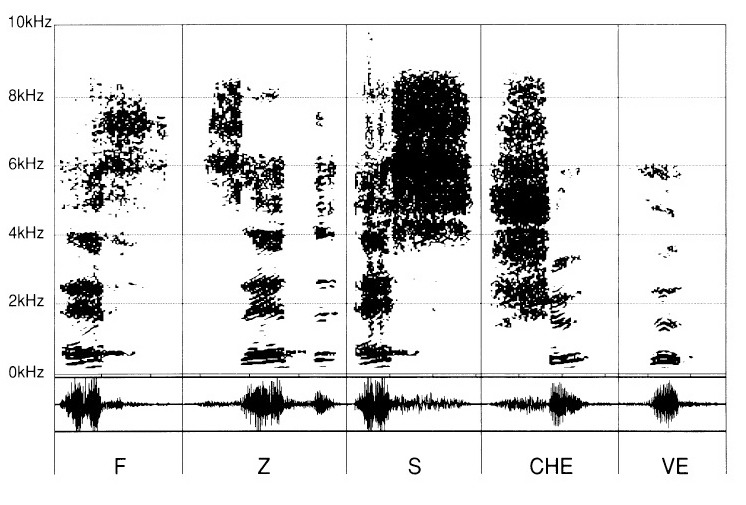
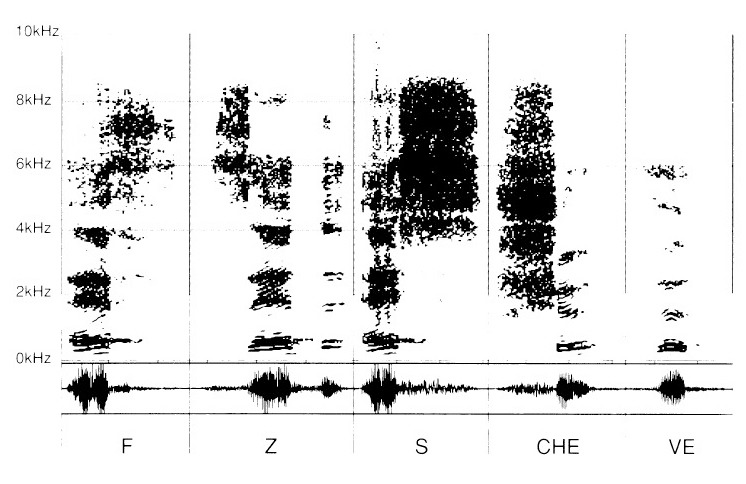
Poi a tali vocali saranno aggiunte differenti consonanti: «F», «Z», «S», «CH», e «V»
(fig. 3)
Al fine d’evitare un sovraccarico di documenti, ci accontenteremo d’aggiungere a tali consonanti la vocale «E», quale è abituale di farlo in occasione dell’apprendimento della lettura delle lettere.
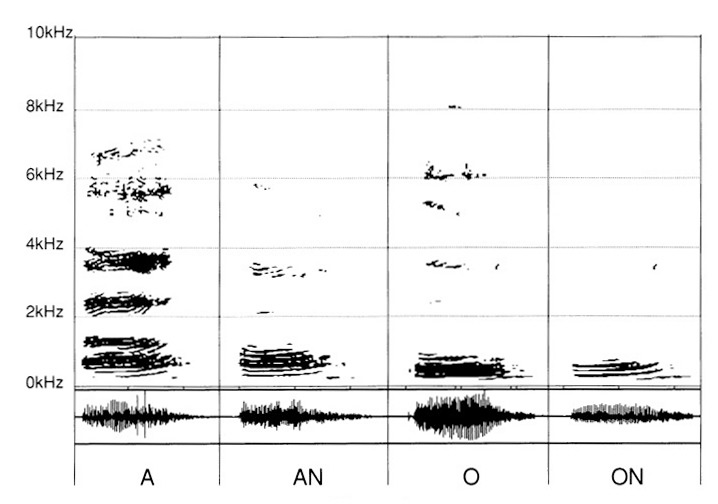
In un ultimo tempo, riportiamo i suoni risultanti dall’aggiunta di «N» dopo «A», «O».
(fig. 4)
Per tal fatto, la successione delle consonanti è da leggere con una «E». Ci si sforza di percepire i suoni consonantici (in effetti «convocalitici») associati a tale vocale, diciamo, «neutra», al fine di non comportare interferenze tra le consonanti e le vocali.
La «E» è lì come per lanciare la vibrazione d’accensione delle sibilanti pronunciate da allora: «eF», «Ze», «eS», «CHe», «Ve».
Al di fuori del tempo iscritto in ascissa, le frequenze si distendono sull’asse ascendente e consentono di vedere, nella parte bassa di ciascuno dei fonemi, una zona rispondente ai «formanti», parimenti denominati «fondamentali». Essi testimoniano della partecipazione laringea.
A prima vista, è facile constatare quanto la «zona» fondamentale sia differente. Essa si rivela, in ciò, già caratteristica di ciascuno dei differenti suoni. In parti alte, i grafici si distinguono tra loro per «zone» specifiche di ciascuna vocale. Tali zone frequenziali sono tanto più acute in quanto ci si avventura verso l’alto della distensione dello spettro di frequenze.
La «A» appare più ricca a livello dei fondamentali e delle armoniche soprastanti della «O». La «I» è particolarmente densa negli acuti, oltre la soglia di 2 kHz.
L’«Ou» si presenta come una «O» meno «brillante», con falla equivalente nelle armoniche elevate.
Le consonanti sibilanti «eF», «Zed», «eS», «CHe», «Ve», si differenziano parimenti tra loro per i loro caratteri propri. Tuttavia, esse hanno un denominatore comune che già conosciamo ritrovando il grafismo della «E».
Per contro, la parte delle sibilanti si rivela singolare per ciascuna di esse mediante una zona più o meno densa negli acuti, a partire da 2 kHz.
Tale insieme di grafici consente di visualizzare le esigenze relative all’integrazione dei diversi fonemi.
Rammentiamo di sfuggita che integrare un suono significa procedere a una registrazione di grande qualità e assicurarsi di una riproduzione all’identico, dunque «ad integrum». Si tratta, insomma, di riprodurre il modello. Per pervenirvi, due condizioni sono indispensabili:
-
L’una che vuole che l’ingrammazione si faccia senza distorsione,
-
l’altra che richiede che la riproduzione sia di una qualità identica, senza alcuna alterazione, segnatamente all’atto dell’emissione.
È, lo si vede, il problema cui sono confrontati tutti coloro che hanno per scopo di raccogliere i suoni, la musica, la parola, i rumori, insomma il mondo sonoro. Sin dall’istante in cui si resta sul piano puramente materiale a proposito della registrazione, la cosa è evidente.
Ma, fatto curioso, per la trasposizione di tali medesimi fenomeni che toccano l’integrazione e che fanno appello all’acquisizione del linguaggio, una barriera alla comprensione si erige come se subitamente fosse occultato il microfono uditivo che gioca tuttavia a doppio titolo:
-
da un lato, all’atto della registrazione,
-
dall’altro, al momento dell’emissione in quanto captatore dell’anello di controllo.
Ci accontenteremo di dare alcuni accenni, facili da decriptare graficamente, concernenti i problemi più correnti, e quelli che complicano drammaticamente la vita scolastica del bambino non consentendogli di assorbire i segnali sonori nella loro «integralità», né tanto meno di riprodurli nella loro pienezza.
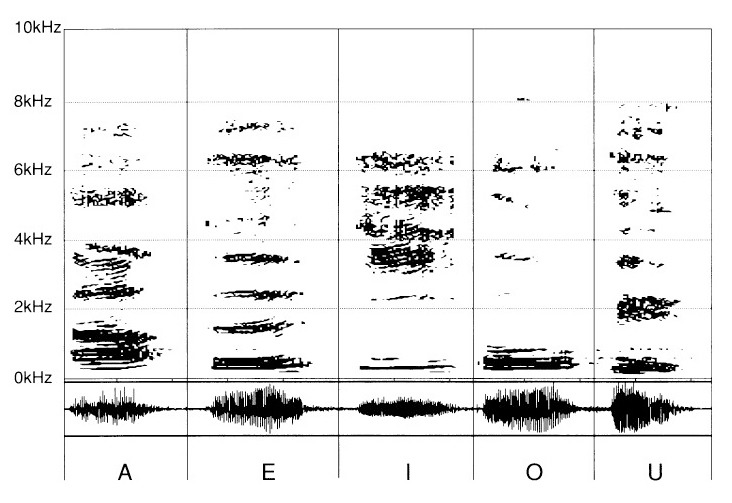
In tale contatto iniziale, prenderemo il caso semplice di un’assenza d’ascolto negli acuti, a partire da 2 kHz per esempio.
Per coloro che sono abituati ad affrontare il concetto d’ascolto, ciò significa:
-
O bene presentare una deficienza uditiva più o meno accentuata del tipo percettivo,
-
o bene avere una selettività non aperta a partire da tale livello, vale a dire, essere incapaci di procedere all’analisi frequenziale a partire da 2 kHz.
Sui grafici che seguono, gli acuti deficitari sono stati rappresentati con una zona ombreggiata. La si può immaginare più o meno ombreggiata, dunque più o meno accentuata.
Le vocali «A», «E», «I», «O» e «U» (fig. 5) perdono del proprio splendore. Senza dubbio, la loro percezione sarà smorta, ma è al livello dell’emissione che il fenomeno è più notevole. In effetti, le differenze pertinenti perdono considerevolmente dei loro segni distintivi. Il che si traduce in una pronuncia difettosa.
Per le sibilanti «F», «Z», «S», «CH» e «V», (fig. 6) le loro caratteristiche differenziali spariscono, lasciando sussistere soltanto la parte non pertinente, sicché diviene se non impossibile, in ogni caso delicato distinguere in modo corretto le diverse sibilanti.
Si sa quanto tale confusione sia frequente. Si sa anche quanto tali problemi si risolvano allorché la selettività è aperta da un’educazione uditiva, senza per ciò fare altra cosa sul piano pedagogico.
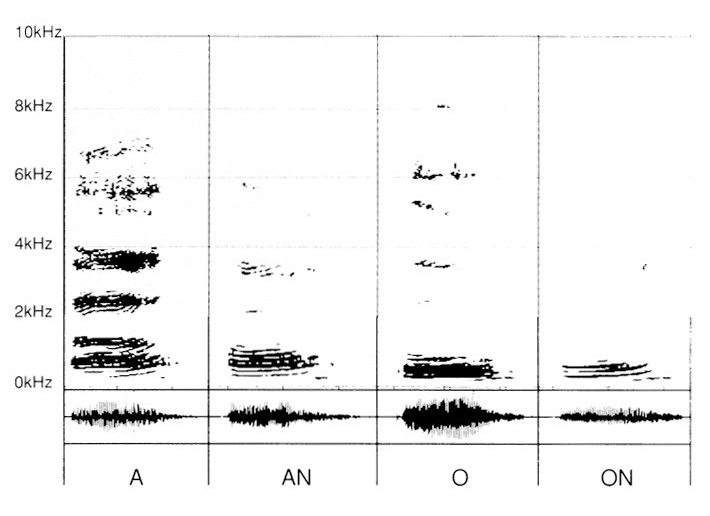
Presso il bambino, un altro scoglio risiede nell’impossibilità di percepire la differenza tra la «A» e la «An», la «O» e la «ON».
Là ancora, le registrazioni danno informazioni significative, nel senso che esse mettono in evidenza i tratti differenziali tra ciascuna delle due vocali che già conosciamo «A» e «O» e la loro risultante «AN» e «ON» mediante aggiunta della «N».
Per un ascolto aperto che funziona senza distorsione né chiusura della selettività, nessun problema. È praticamente impossibile non percepire la differenza.
Per contro, per un’audizione non ancora pervenuta all’apertura della selettività, come nel caso precedente, con dunque una zona di non discriminazione a partire da 2 kHz, la confusione diviene evidente. (fig. 7)
-
Per discernere tra «O» e «ON», è veramente difficile pervenirvi.
-
Per «A» e «AN» la risposta può essere aleatoria grazie a una differenziazione ancora resa possibile. Effettivamente, vi si scopre una certa differenza di densificazione nei formanti e nelle frequenze comprese tra 500 Hz e 2 kHz. Se la selettività è bloccata a 1 kHz, allora l’analisi, persino attenta, diviene assai delicata.

Alfred Tomatis, Parigi, 2 aprile 1992