Phonemes in the Spotlight
A little phonetics
On the occasion of a status review of the speech-therapy work of a member of the network, the sonographic analysis of certain phonemes was carried out by Professor Tomatis in his Parisian laboratory.
Phonetic differentiations incontestably form part of the professional preoccupations of speech therapists. They are, in fact, only auditory differentiations in face of a sound, and a fortiori in face of language. The latter is composed of a succession of sounds which determine the spoken chain: a linking of letters, syllables, words, constituting the sentence from which emerges the global signification, which itself springs from the semantic values of each of the verbal components. The composition of the context grants, in the end, the meaning of the engaged structure, sustained by the rhythm and intonation of the verbal flow.
This shows how important the participation of audition is.
It seems useful to us to recall the essential elements at play in the ear:
-
First of all, when it presents itself as it should be, it spreads, according to the physiological curve (of Fletcher), from the low to the high frequencies on a spectrum extending from 16 to 16,000 cycles per second,
-
it profiles itself on a curve presenting no distortion,
-
it can, if it engages itself in listening, decompose the sounds reaching it, both those of the spoken chain and those of the musical phrase. Let us say in passing that, on this particular point, language for its part is constructed on a musicality specific and characteristic to each of the idioms,
-
selectivity must be taken into account. It is an important quality of the ear which demands some complementary information, since it is unusual. It corresponds to the possibility the ear has of succeeding not only in differentiating tonal heights but also in distinguishing the direction of variations from one sound to another. It is in sum the frequency discriminative power which characterises this particularity,
-
auditory laterality is also to be analysed, for it plays upon the sequential discriminative power of the sentence,
-
it is necessary to recall that languages, whichever they may be, must adapt to the listening possibilities of the different ethnic groups.
It would occur to no one to maintain that oral language could have its origin in a society composed of deaf-mutes. It could only have been generated by hearers, better still by listeners, by true “phoneticians”. And one remembers the assertion of Daniel Jones in his work An Outline of Phonetics where he specifies that one could in no way claim to be a phonetician without being endowed with a perfect ear. In sum, an ear answering to the characteristics we have just signalled.
Moreover, the “pertinent” phonetic differentiations, evidenced by the Prague School and explicated by Trubetzkoy in his work on “Phonology”, only define the “linguistic channels”, which are in reality only auditory “channels”.
The most flagrant proof is given by the phonetic deformations observed in the child with significant auditory deficits. According to the location of the latter on the scale of the acoustic spectrum, it is easy to foresee what will be the pronunciation defects. A significant deficiency in the high frequencies is certainly a great handicap for integrating the sibilants and, in consequence, for reproducing them spontaneously.
This being said, it is easy to visualise the parallelism which binds phonetic integration and auditory perception. The ear can well be assimilated to a filter which ensures integration in function of its potentialities. It will thus translate the effects provoked by the defects of its response curves, even if, on first analysis, these might appear minor. It is thus that, even if the phonetic deformations are scarcely detectable to an unaccustomed, not very expert ear, they will inevitably manifest themselves during the setting in operation of more complex processes such as those of reading and spelling.
We now take up the work proper of the sonographic studies of phonemes.
Commentary on the phonemes
The study bears on phonemes of the French language. The analyser adopted is the sonograph.
The latter allows the evidencing of:
-
the time of development of the phoneme,
-
the frequency analysis of this phoneme in function of the temporal flow,
-
the intensity.
-
Time is inscribed on the x-axis,
-
the frequencies on the “y” axis. The analysis here goes up to 10 kHz (see fig. 1)
-
the intensity is read in function of the more or less marked blackness of the frequency line. Thus, each frequency manifests itself with its relative intensity with respect to the whole.
Various sounds were gathered by way of example. Of course, one can at will apply what we present on a vast scale, but the primordial elements are already highlighted with the chosen tracings.
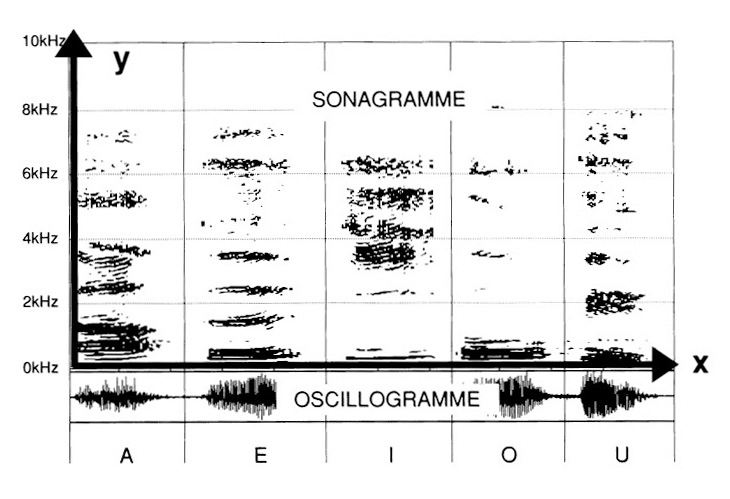
(fig. 1)
First, the vowels are recorded: “A”, “E”, “I”, “O” and “U”.
(fig. 2)
Then onto these vowels different consonants will be added: “F”, “Z”, “S”, “CH”, and “V”
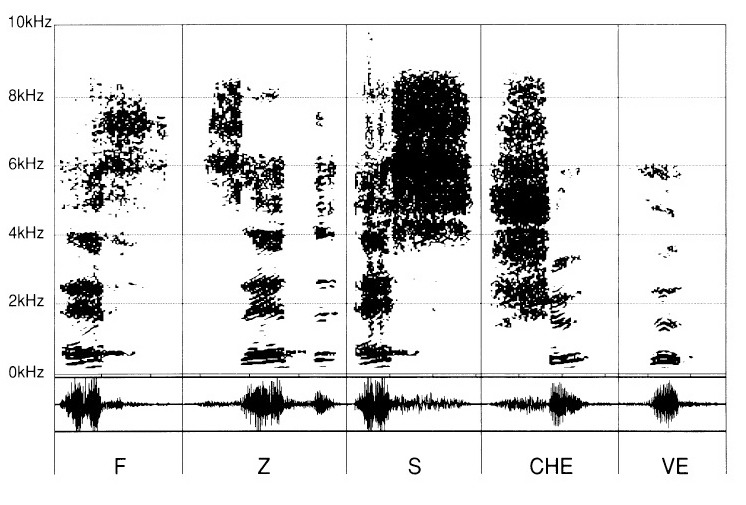
(fig. 3)
To avoid an overload of documents, we shall content ourselves with adding to these consonants the vowel “E”, as is customary in the learning of the reading of letters.
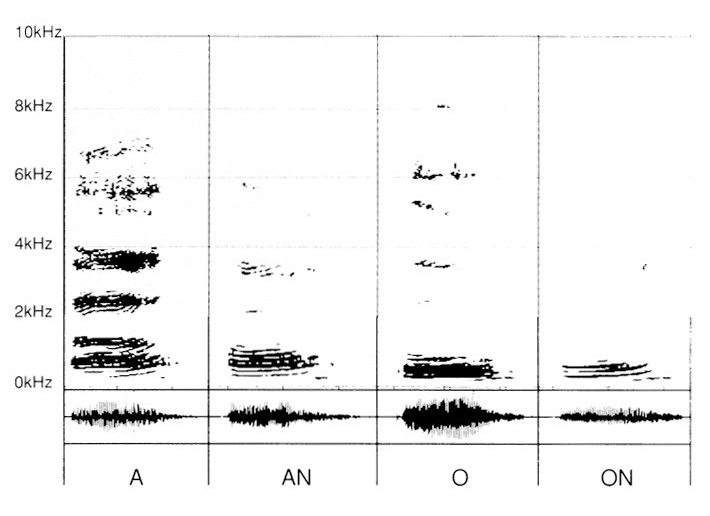
In a last stage, we report the sounds resulting from the adjunction of “N” after “A”, “O”.
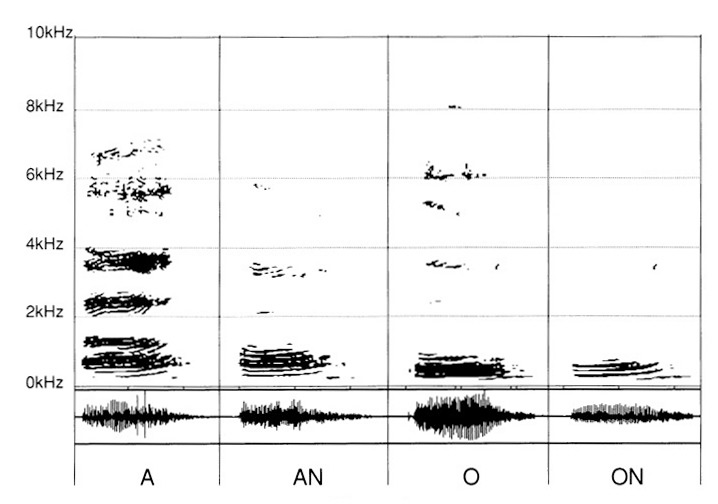
(fig. 4)
Thereby, the succession of consonants is to be read with an “E”. One endeavours to perceive the consonantal sounds (in fact “co-vocalic”) associated with this so-called “neutral” vowel, in order not to bring about interferences between the consonants and the vowels.
The “E” is there as if to launch the kindling vibration of the sibilants pronounced thereafter: “eF”, “Ze”, “eS”, “CHe”, “Ve”.
Beyond time inscribed on the abscissa, the frequencies spread out on the ascending axis and allow seeing, in the lower part of each of the phonemes, a zone corresponding to the “formants”, also called “fundamentals”. They testify to laryngeal participation.
At first glance, it is easy to observe how much the fundamental “zone” is different. It proves, in that, already characteristic of each of the different sounds. In the upper part, the graphics distinguish themselves from one another by “zones” specific to each vowel. These frequency zones are all the higher as one ventures towards the top of the spread of the spectrum of frequencies.
The “A” appears richer at the level of the fundamentals and the supra-jacent harmonics than the “O”. The “I” is particularly dense in the highs, beyond the 2 kHz threshold.
The “Ou” presents itself as a less “brilliant” “O”, lacking equivalence in the high harmonics.
The sibilant consonants “eF”, “Zed”, “eS”, “CHe”, “Ve” also differ from one another by their proper characters. However, they have a common denominator that we already know, in finding the graphical pattern of the “E”.
By contrast, the part of the sibilants reveals itself singular for each of them by a more or less dense zone in the highs, from 2 kHz onwards.
This set of graphics allows the visualisation of the requirements relating to the integration of the various phonemes.
Let us recall in passing that to integrate a sound means to proceed to a recording of great quality and to ensure an identical reproduction, that is, “ad integrum”. It is, in sum, a question of reproducing the model. To attain this, two conditions are indispensable:
-
the one, which requires that the engramming be made without distortion,
-
the other, which demands that the reproduction be of identical quality, without any alteration, notably at the time of emission.
This is, as we see, the problem with which all those whose aim is to gather sounds, music, speech, noises — in short, the sonic world — are confronted. From the moment one remains on the purely material plane concerning recording, the matter is obvious.
But, curiously, for the transposition of these same phenomena touching on integration and which call upon the acquisition of language, a barrier to comprehension rises, as though the auditory microphone — which yet operates on a double count — were suddenly occulted:
-
on the one hand, during recording,
-
on the other, at the moment of emission as a receptor of the monitoring loop.
We shall content ourselves with giving some glimpses, easy to decipher graphically, concerning the most common problems, and those which dramatically complicate the school life of the child by not allowing him to absorb the sonic signals in their “integrality”, any more than to reproduce them in their plenitude.
In this initial contact, we shall take the simple case of an absence of listening in the highs, from 2 kHz for instance.
For those accustomed to approaching the concept of listening, this means:
-
either presenting an auditory deficiency more or less marked of the perceptive type,
-
or having a selectivity not open from this level — that is, being incapable of carrying out frequency analysis from 2 kHz onwards.
In the graphics that follow, the deficient highs have been represented by a shaded zone. One can imagine it more or less shaded, and therefore more or less pronounced.
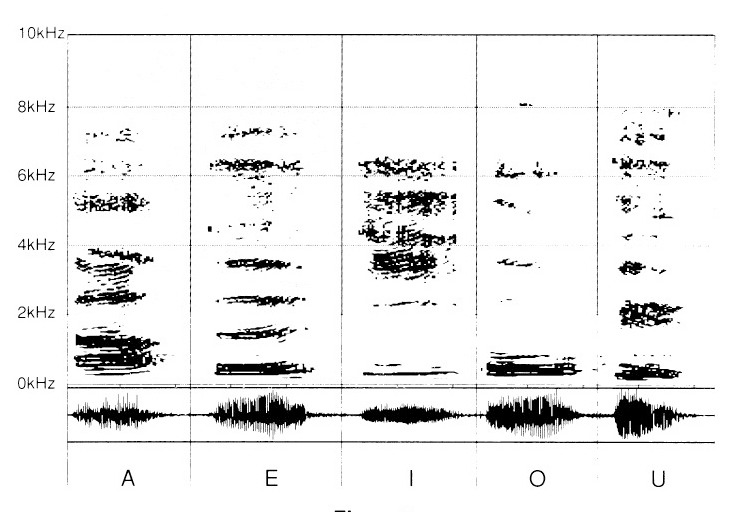
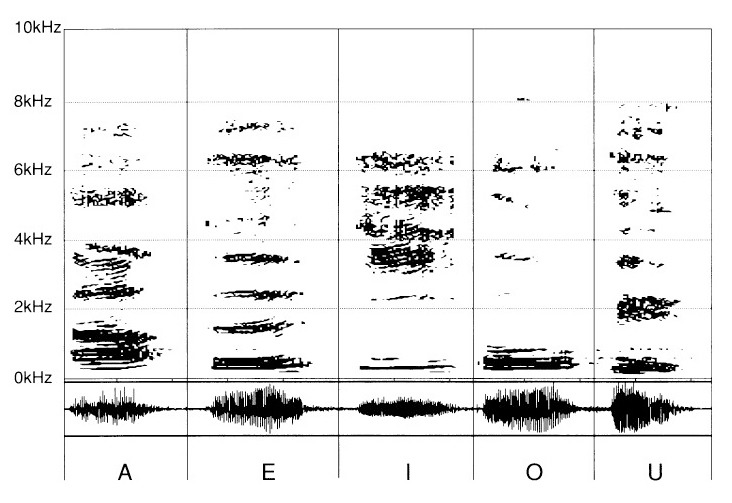
The vowels “A”, “E”, “I”, “O” and “U” (fig. 5) lose their brilliance. Doubtless their perception will be dull, but it is at the level of emission that the phenomenon is most remarkable. Indeed, the pertinent differences considerably lose their distinctive signs. Which translates into a defective pronunciation.
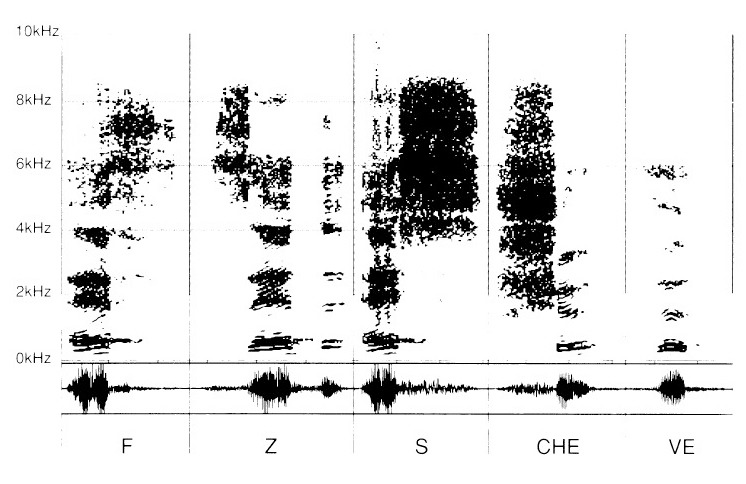
For the sibilants “F”, “Z”, “S”, “CH” and “V” (fig. 6), their differential characteristics disappear, leaving only the non-pertinent part to subsist, so that it becomes, if not impossible, at least delicate to distinguish correctly the various sibilants.
It is known how frequent this confusion is. It is also known how these problems are resolved when selectivity is opened by an auditory education, without thereby doing anything else on the pedagogical plane.
In the child, another stumbling block resides in the impossibility of perceiving the difference between “A” and “An”, “O” and “ON”.
There again, the recordings give significant information, in the sense that they evidence the differential traits between each of the two vowels we already know, “A” and “O”, and their result “AN” and “ON” by the addition of “N”.
For an open listening functioning without distortion or closing of selectivity, no problem. It is practically impossible not to perceive the difference.
By contrast, for an audition not yet arrived at the opening of selectivity, as in the previous case, with therefore a zone of non-discrimination from 2 kHz onwards, the confusion becomes evident. (fig. 7)
-
To decide between “O” and “ON”, it is really difficult to achieve.
-
For “A” and “AN” the answer may be uncertain thanks to a still possible differentiation. Indeed, one discovers in it a certain difference of densification in the formants and the frequencies lying between 500 Hz and 2 kHz. If selectivity is blocked at 1 kHz, then the analysis, even attentive, becomes very delicate.

Alfred Tomatis, Paris, 2 April 1992